A customer using your AI agent doesn't think about tokens, context windows, or KV cache compression. They think about the three seconds they spent staring at a spinning cursor.
Three seconds is the threshold. Below it, interaction feels responsive. Above it, it starts to feel broken. Above ten seconds, users disengage entirely.
This is the real-time inference problem for AI agents. And it's one of the least-discussed engineering challenges in the industry.
Why Agentic Inference Is Different from Chat Inference
Traditional LLM inference optimization targets a specific pattern: a user sends a prompt, the model generates a response, the session ends. You optimize for single-request latency and cost.
Agentic inference is different. Agents make multiple LLM calls per task. They have tool execution overhead between calls. They maintain state across long conversations. They're often serving many concurrent users simultaneously.
This creates a fundamentally different optimization landscape:
Multi-Call Per-Task
A simple customer service agent might make 3-5 LLM calls per user message (intent classification, context retrieval, response generation, safety check, formatting). A complex research agent might make 50+ calls. Each call adds latency.
If each call takes 1 second, a 5-call task takes 5+ seconds. A 50-call task takes 50+ seconds. The model latency compounds with call count.
Tool Execution Overhead
Between LLM calls, agents execute tools — web searches, database queries, code execution, API calls. These have their own latency, often measured in hundreds of milliseconds to seconds.
Context Window Pressure
As agents run longer, their context grows. A research agent processing a 50-turn conversation has to process increasingly long context windows on every LLM call. This is the context-window-pressure problem: latency increases as sessions get longer.
Concurrent Users
A chatbot serves one user at a time per model instance. A production agentic system serves hundreds or thousands of concurrent users, each with their own session state, tool calls, and latency requirements.
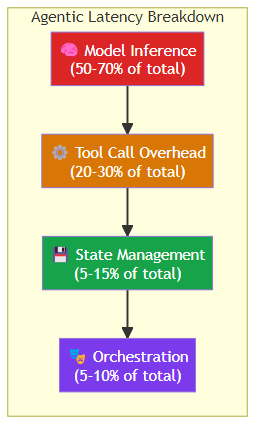
The Components of Agentic Latency
Breaking down where latency comes from in a typical agentic pipeline:
1. Model Inference Time
The raw time to generate an LLM response. This is what most inference optimization focuses on:
- Time to first token (TTFT): How quickly does the model start generating?
- Time per output token (TPOT): How fast is each subsequent token?
- Total generation time: TTFT + (TPOT × output token count)
For a 500-token response: if TTFT is 200ms and TPOT is 20ms/token, total generation is 200 + (20 × 500) = 10.2 seconds. That's already too slow for interactive use.
2. Tool Call Overhead
The time between when an agent decides to call a tool and when it receives the result:
- Tool dispatch latency: The infrastructure overhead of routing the tool call to the right execution environment
- Sandbox startup time: For code execution tools, the time to spin up a container or sandbox
- External API latency: For web search, database queries, etc., the upstream service's response time
- Result processing: Time to parse, validate, and format tool results before returning them to the agent
Tool overhead typically adds 100ms-2s per tool call.
3. State Management Overhead
The time to load, update, and persist agent session state:
- Context retrieval: Fetching conversation history and memory from storage
- State serialization: Converting agent state to the format needed for the next LLM call
- Checkpoint persistence: Saving state for resumability (critical for long-running agents)
State management adds 10-100ms per LLM call in production systems.
4. Orchestration Overhead
The infrastructure layer that coordinates everything:
- Request routing: Directing requests to appropriate model instances
- Model load balancing: Managing traffic across multiple model replicas
- Rate limiting and quota enforcement: Preventing individual users or agents from exceeding budgets
Orchestration overhead is typically 5-20ms but can spike under load.
Optimization Strategies for Agentic Inference
Strategy 1: Streaming Everything
The single highest-impact optimization: stream model responses to the user as tokens are generated. This doesn't reduce total latency, but it eliminates perceived latency by giving users immediate feedback.
With streaming, a 10-second response starts showing content within 200ms instead of waiting 10 seconds for the full response. For agentic systems, streaming is not optional — it's the difference between a usable system and an unusable one.
Strategy 2: Intelligent Model Routing
Not every LLM call needs the same model. A simple intent classification can use a 7B-parameter model in 50ms. A complex reasoning task needs a 400B+ reasoning model and might take 30 seconds.
Route calls by complexity:
- Intent classification: small, fast, cheap model
- Tool call generation: medium model
- Complex reasoning: large, capable model
- Safety validation: small, deterministic model
The performance and cost gains from routing are dramatic: 70-90% of LLM calls can go to smaller, faster, cheaper models with no quality degradation.
Strategy 3: Context Management
The context-window-pressure problem is real and growing as agents run longer. Solutions:
- Semantic compression: Identify and remove low-relevance context while preserving key information
- Summarization: Periodically compress long conversation history into a distilled summary
- Sliding window: Only keep the most recent N turns plus a summary of older context
- Hierarchical memory: Keep recent interactions in fast storage, older ones in slower but larger storage
Context management can reduce per-call latency by 30-60% for long sessions.
Strategy 4: Tool Call Optimization
Tool execution is often the largest single source of latency. Optimize it:
- Pre-warm sandboxes: Keep code execution environments pre-warmed so startup time is near-zero
- Connection pooling: Reuse HTTP connections for API-based tools
- Parallel tool calls: When an agent needs data from multiple independent tools, execute them in parallel instead of sequentially
- Tool result caching: Cache results of repeated tool calls (e.g., the same web search in a conversation)
Strategy 5: Speculative Execution
When an agent is highly likely to make a certain tool call, start executing it before the LLM confirms. For example:
- A customer service agent that always searches the knowledge base after classification can pre-execute that search
- A coding agent that always runs tests after implementation can pre-warm the test environment
Speculative execution can reduce effective latency by 200-500ms for predictable tool patterns.
The Concurrent User Problem
The hardest part of agentic inference at scale isn't per-request latency — it's maintaining low latency under concurrent load.
A single agentic request might use 500ms of compute time. But if you're serving 1,000 concurrent users, you need to handle 1,000 of those requests simultaneously without queuing delays.
This requires:
- Horizontal scaling: Run enough model instances to handle peak load
- Request queuing with SLAs: If requests queue, enforce maximum wait times and reject or degrade gracefully if exceeded
- Isolation: Prevent noisy neighbor effects where one high-load user impacts others
- Load shedding: Under extreme load, drop low-priority requests to protect core functionality
What 100ms vs 1s vs 10s Means for UX
The practical impact of inference latency on user experience:
| Latency | User Perception | Agentic Use Case |
|---|---|---|
| < 100ms | Instantaneous | Simple intent classification, button responses |
| 100-500ms | Responsive | Tool calls, short responses |
| 500ms-2s | Noticeable wait | Moderate tool chains, standard responses |
| 2-5s | Frustrating | Complex reasoning, multi-step tools |
| 5-10s | Uncomfortable | Long tool chains, deep research |
| > 10s | Broken | Essentially unusable for interactive agents |
For interactive agents, target P99 latency under 2 seconds for simple tasks and under 5 seconds for complex ones.
The Architecture Decision That Matters Most
Most latency problems in agentic systems aren't caused by the LLM — they're caused by architecture choices:
- Synchronous tool calls: Calling external APIs synchronously blocks the entire agent pipeline. Use async tool calls with callbacks.
- Sequential processing: Processing tool results one at a time when they could be parallelized.
- No streaming: Waiting for full model responses instead of streaming tokens.
- Over-fetching context: Loading far more context than necessary for the current step.
- No caching: Repeating identical work (same searches, same computations) multiple times.
These are all architectural issues that can be solved without changing the underlying model.
The Bottom Line
Real-time inference for AI agents is a solved problem — it's just that the solution requires engineering discipline across multiple layers: model optimization, tool execution, state management, and system architecture.
The teams building fast, reliable agentic systems share common practices:
- Stream everything — eliminate perceived latency
- Route by complexity — use the right model for each task
- Compress context — prevent window pressure from degrading performance
- Parallelize tools — don't wait for independent operations sequentially
- Cache aggressively — eliminate repeated work
The LLM is the slowest part of your pipeline by design. Everything else should be engineered to get out of its way as quickly as possible.
Related posts: Observability for AI Agents — the observability framework for production agentic systems. AI Agent Infrastructure Readiness — the broader infrastructure picture for agentic systems. The Missing Discipline: AI Agent Harness Engineering — how execution layer architecture affects performance.


