The headlines this week told a familiar story: another AI company raised billions, another model broke a benchmark, another lab announced a breakthrough. But underneath the noise, a quieter story was unfolding — one that matters far more for anyone actually deploying AI agents in production.
Nebius Group is acquiring Eigen AI for $643 million. Sierra AI closed a $950 million Series C. Cerebras filed for an IPO at a reported $10+ billion valuation. The Pentagon signed $800 million in AI infrastructure contracts with Nvidia, Microsoft, and AWS. Across the board, capital is flooding into the layer beneath the model.
That layer is AI agent infrastructure. And it's the real bottleneck.
The Infrastructure Gap Nobody Talks About
Every week brings a new reasoning model, a new context window record, a new benchmark topper. Less discussed is what happens after you pick your model and start building an agentic system that needs to:
- Maintain state across thousands of concurrent users
- Handle tool calls with sub-second latency
- Scale elastically from zero to millions of requests
- Stay available when a cloud provider has an outage
- Process sensitive data without leaking it
- Keep costs predictable as usage grows
These aren't model problems. They're infrastructure problems. And they're the reason most AI agents fail in production — not because the LLM hallucinated, but because the infrastructure around it fell over.
What's Actually Needed for Agentic Infrastructure
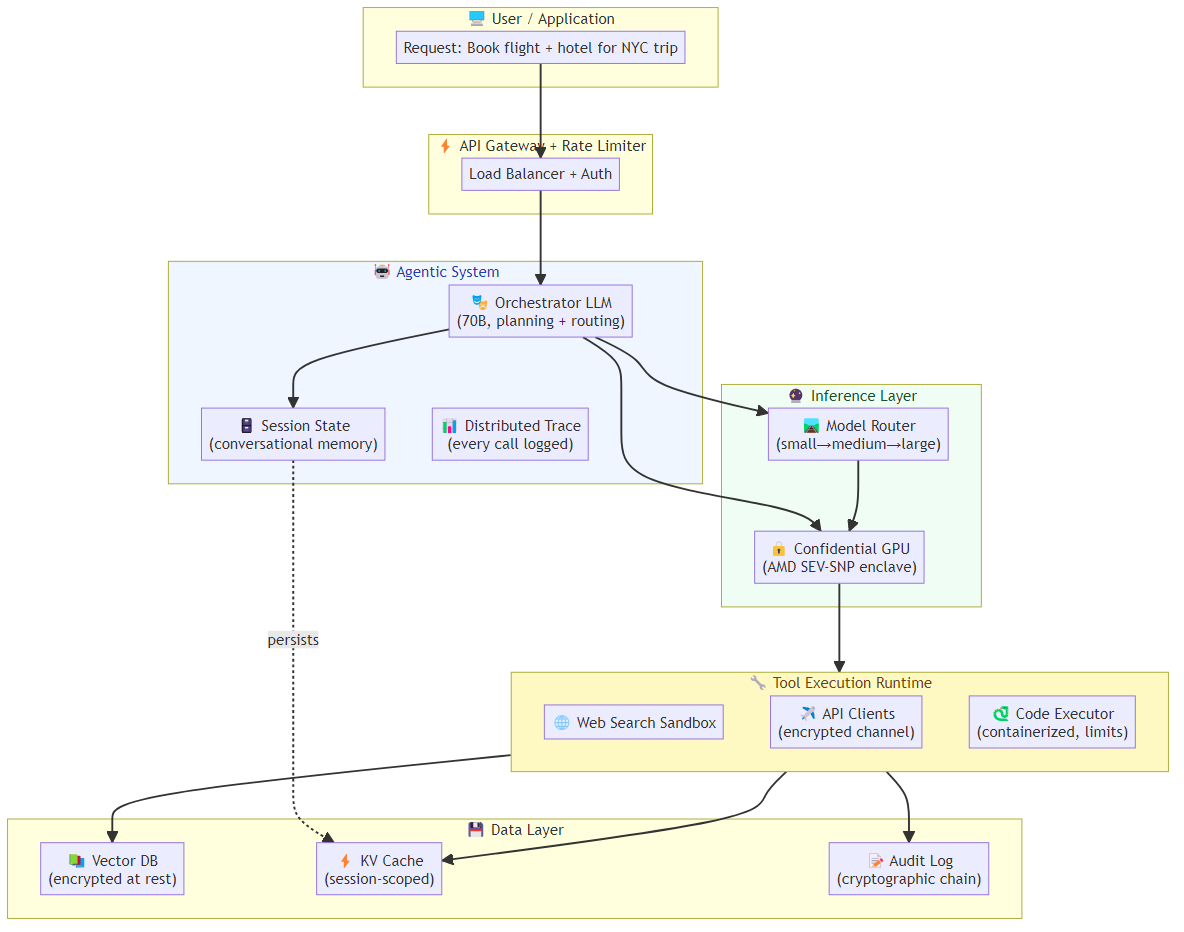
1. Inference Orchestration
Your AI agent doesn't just call a single model endpoint. It needs:
Model routing: Route simple queries to a fast, cheap model; complex tasks to a capable one. An agent handling customer support might use a 7B model for intent classification, a 70B model for response generation, and a small model again for safety checking.
Concurrent request management: Unlike a chatbot (one user, one request), agents handle multiple tool calls simultaneously. Your infrastructure must queue, parallelize, and timeout gracefully.
Streaming state management: Long-running agentic tasks need checkpointing — saving state so a server restart doesn't wipe a half-completed workflow.
2. Tool Execution Runtimes
When your agent decides to call a tool — web search, code execution, database query, API call — that tool needs to run somewhere. Production agentic systems need:
Isolated execution environments: Code execution can't happen in the same process as your LLM inference. Containers, sandboxes, or serverless functions are the norm. The overhead of spinning up a sandboxed environment for a 50ms tool call is non-trivial.
Resource budgets: An agent with a code interpreter tool is a potential resource exhaustion attack surface. You need per-call CPU, memory, and time limits.
Retry and circuit breaker logic: Tool calls fail — rate limits, network timeouts, upstream API errors. Your infrastructure needs exponential backoff, fallback strategies, and graceful degradation.
3. Memory and State Management
Agents are stateful by design. They maintain conversation history, accumulate tool call results, build up artifacts, and track progress toward goals. This state needs to live somewhere:
- Vector stores for semantic retrieval
- Key-value stores for fast session state
- Distributed cache for multi-instance deployments
- Long-term memory for agents that need to persist knowledge across sessions
The architectural choices here — ephemeral vs. persistent, in-memory vs. distributed, monolithic vs. microservices — compound quickly. Get them wrong and you'll spend months debugging race conditions and cache incoherence.
4. Observability and Debugging
This is where most teams underestimate the challenge. Traditional software debugging is hard enough. Debugging an AI agent is a different beast:
Agent trace visualization: A single user request can trigger 50+ LLM calls, 20+ tool executions, and multiple state transitions. You need end-to-end traces.
Cost attribution: Every token has a cost. Per-user, per-request, per-agent-type cost breakdown is essential for unit economics.
Quality monitoring: How do you know when your agent starts degrading? You need automated evaluation pipelines, not just user feedback.
Anomaly detection: Agents can exhibit emergent failure modes — looping behavior, prompt injection exploitation, tool call cascades — that don't exist in traditional software.
5. Security Boundaries
Agents with tool access are powerful — and dangerous. Production infrastructure needs:
- Network isolation: Agent tool executions should run in isolated network namespaces
- Data governance: PII handling, data residency, audit logs
- Prompt injection defense: Adversarial user inputs designed to manipulate agent behavior
- Least-privilege tool access: Agents should only have access to the tools they absolutely need
The Infrastructure-as-a-Product Shift
What's changing in 2026 is that infrastructure is no longer an afterthought — it's becoming the product. The companies raising massive rounds aren't primarily building better models. They're building:
- Inference clouds optimized for agentic workloads (Nebius/Eigen AI)
- Enterprise AI platforms with built-in compliance, observability, and security (Sierra AI)
- Specialized AI hardware for lower-latency inference (Cerebras)
This is the commoditization of AI infrastructure — and it's a necessary one. Just as the cloud abstracted away server management, AI infrastructure abstractions are emerging to hide the complexity of deploying, scaling, and operating agentic systems.
What This Means for Your AI Agent Project
If you're building an AI agent in 2026, the question isn't "which model should I use?" — it's "how will I run it at scale, reliably, securely, and cost-effectively?"
The gap between a prototype that works in a notebook and a production system that serves 10,000 concurrent users is enormous. That gap is infrastructure.
Before you spend months fine-tuning a model, ask yourself:
Can your inference stack handle 1000 concurrent requests with P99 latency under 2 seconds? If not, optimize inference first.
Do you have observability into every tool call, every state transition, every LLM call? If not, instrument before you scale.
What's your failure mode when your LLM provider goes down? If the answer is "the agent stops working," you need fallback strategies.
Have you stress-tested your tool sandbox? A code interpreter with no resource limits is a liability.
Can you explain why each agent decision was made? If not, you need tracing and auditability before deployment.
The Bottom Line
The AI infrastructure market will be worth over $1 trillion by 2030. But the real opportunity — and the real challenge — is in making that infrastructure agent-ready.
The battleground for AI value isn't the model. It's the system around it.
For deep-dive on the latency problem that makes agentic infrastructure challenging — real-time inference optimization, model routing, and context management — see Real-Time Inference for AI Agents.
Related posts: Agentic RAG — extending retrieval to agentic systems. Agent Evaluation Metrics — measuring what matters in AI agent performance. Building Resilient Agents — graceful degradation and circuit breakers.


