The most consequential race in AI right now isn't between language models — it's between the chips that run those models.
Cerebras, the chip maker that builds the world's largest processor (a single wafer-scale chip with 850,000 AI cores), is preparing for a blockbuster IPO. The company has been quietly essential to AI infrastructure: it powers OpenAI's inference workloads, competes with Nvidia's H100 for training and inference contracts, and represents a fundamentally different architectural bet on what AI compute should look like.
The IPO will put a spotlight on the AI chip infrastructure layer — the foundation that every agentic AI system runs on, and the bottleneck that determines which AI applications are economically viable and which aren't.
Why the Chip Architecture Matters for Agentic AI
Agentic AI systems have different compute profiles than static model inference. A chatbot processes a single request and returns an answer. An agentic system processes a request, calls tools, re-reasons, calls more tools, synthesizes results — often executing dozens of inference calls per task.
This changes the economics and the requirements:
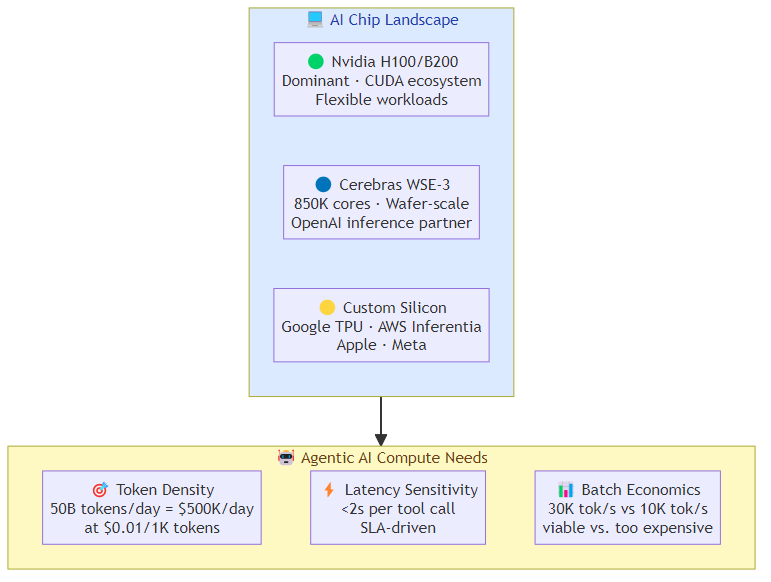
Token density: agentic tasks consume far more tokens than static inference tasks. A single agentic request might generate 10-50x more tokens than a comparable chatbot request, because the agent is doing multi-step reasoning and tool orchestration rather than single-shot generation.
Latency sensitivity: agents that call tools synchronously need low per-call latency. A 2-second inference call doesn't matter for a chatbot. It matters enormously when that call is one of twenty in a chain that determines whether the agent completes a task within the SLA window.
Batch economics: at high volumes, the difference between a chip that processes 10,000 tokens per second versus 30,000 tokens per second is the difference between an economically viable agentic deployment and one that's too expensive to run.
These requirements favor different architectural decisions than training-optimized chips, which is why the inference chip market is getting as much attention as the training market.
The Three Horses in the AI Chip Race
Nvidia
Nvidia's H100 and the newer B200 remain the dominant force in AI compute. Their CUDA ecosystem is the reason Nvidia is hard to displace — the software stack, the library support, the cloud provider relationships, and the model compatibility are all deeply entrenched.
For agentic AI specifically: Nvidia's advantage is in the flexibility to handle diverse workloads, the established cloud instance availability, and the broad model compatibility. The disadvantage is price — H100 instances are expensive, and at the token volumes that agentic AI generates, the cost per task can be problematic for high-volume use cases.
Cerebras
Cerebras takes a radically different approach: instead of networking together thousands of small chips, it builds one enormous chip that fits an entire neural network on a single wafer. The Wafer Scale Engine 3 has 850,000 AI cores and 2.6 trillion transistors on a single piece of silicon.
For agentic AI: Cerebras's advantage is raw inference throughput — it can process massive amounts of memory bandwidth in a way that smaller chips can't match. This matters for the memory-intensive operations that large language models perform during inference. The company's relationship with OpenAI means their chip is proven at the highest scale of AI deployment.
The IPO will reveal whether Cerebras has the commercial traction to be a durable alternative to Nvidia, or whether the architecture advantage is real but the ecosystem and commercial execution are harder.
Custom Silicon (Google TPUs, AWS Trainium/Inferentia, Apple, Meta)
Every major tech company is building or has built custom AI chips optimized for their specific workloads. The pattern is consistent: when a workload is large enough and predictable enough, custom silicon beats general-purpose chips on cost and performance per watt.
For agentic AI: custom silicon is a factor primarily for the companies that have enough volume to justify the development cost. Google TPUs handle Google's internal AI workloads including agentic applications. AWS Inferentia powers a significant fraction of cloud AI inference. These are not general-market alternatives to Nvidia, but they represent a long-term structural shift in how AI compute is provisioned.
The Inference Bottleneck
The chip battle is increasingly concentrated at inference, not training. Training is a bounded problem — you know how much compute you need for a given model, you can plan for it, and the market for training chips is well-established.
Inference is the operational problem: every production AI system runs inference constantly, at scale, paying per token for the life of the deployment. The economics of inference determine whether an AI application can be commercially viable.
For agentic AI, this is especially acute. An agentic system that processes 10 million requests per day at an average of 5,000 tokens per request is consuming 50 billion tokens per day of inference compute. At $0.01 per 1,000 tokens (roughly the cost of Claude Haiku via API), that's $500,000 per day just in inference costs — before you count tool calls, retrieval, or orchestration overhead.
The path to economically viable agentic AI at scale depends on inference cost falling faster than agentic token consumption grows. The chip makers are in a race to drive that cost curve down.
What Cerebras's IPO Signals
The IPO is a signal that the AI infrastructure layer is reaching commercial maturity. A blockbuster IPO for a company whose primary business is AI inference chips tells you that:
- The market is large enough: enterprises and cloud providers are buying AI inference compute at volumes that support a standalone chip company.
- Competition is real: if Nvidia had a monopoly on viable AI inference, Cerebras wouldn't be preparing an IPO — it would be struggling for survival.
- The market wants alternatives: cloud providers and AI companies are actively hedging against Nvidia dependency, which creates space for alternatives like Cerebras.
The wildcard in the IPO is how much of Cerebras's revenue comes from OpenAI specifically. A relationship with a single dominant customer is either a moat (if that customer is locked in) or a concentration risk (if they switch to alternatives). The S-1 filing will reveal this, and it's the number to watch.
The Bottom Line for Agentic AI Builders
The chip infrastructure conversation matters for agentic AI builders for practical reasons:
Cost modeling: when you architect an agentic system, the inference cost per task is a first-order design constraint. The chip layer determines what that cost is and where it's heading. Building agentic applications without understanding the inference cost curve is like building a SaaS product without understanding your compute costs.
Latency architecture: the per-call latency of your inference provider affects your agent's responsiveness and therefore your UX and SLA design. Different chips have different latency profiles at different batch sizes.
Vendor strategy: the AI labs (Anthropic, OpenAI) are making their own chip choices, which affect how their APIs are priced and provisioned. Understanding the chip dynamics helps you predict where API pricing is going.
Long-term positioning: if custom silicon continues to win against general-purpose chips, the AI infrastructure market consolidates around the companies that build their own (Google, Amazon, Meta, Apple). The companies that don't build their own (everyone else) become dependent on chip makers for their economic viability.
The chip battle is infrastructure, but infrastructure determines what's economically possible. For agentic AI, the next phase of competition isn't just about who has the best model — it's about who can run agentic workloads at costs that make them commercially viable at scale.
Related posts: AI Agents in Production — the engineering practices for production agent deployment. Agent Cost Optimization — the engineering side of agent cost optimization. Visual AI Product Strategy — how visual AI models are winning the product race.