The headline sounded definitive: "AI offered more accurate emergency room diagnoses than two human doctors."
The Harvard study that generated this headline is a real research result, and it's been cited in the ongoing debate about AI in healthcare. But headlines like this do more harm than good if they cause clinicians to either over-trust AI diagnostic tools or dismiss them entirely. The reality of AI diagnostic accuracy is more nuanced than the headline suggests, and understanding the nuances matters for anyone building or deploying medical AI systems.
I spent three years at Ai-Bharata deploying medical imaging AI across 270+ healthcare institutions in India. That experience gave me a specific perspective on what "AI is more accurate than doctors" actually means in practice — and what it takes to translate accuracy metrics into clinical value.
What the Harvard Study Actually Measured
The study compared AI diagnostic performance against individual physicians and combinations of physicians on emergency cases. The finding that AI was more accurate than "two human doctors" refers to a specific experimental design: two physicians consulting together versus the AI system independently.
The critical questions the headline doesn't answer:
What was the case mix? Emergency medicine covers an enormous range of conditions, from straightforward presentations to complex multi-system emergencies. A study that skews toward conditions where AI has been extensively trained (common imaging findings, textbook presentations) will show different results than one that includes rare presentations and unusual symptom combinations.
What was the gold standard? Diagnostic accuracy is measured against a ground truth. In many medical AI studies, the gold standard is what the patient was eventually diagnosed with after all testing and follow-up — which is a different standard than what an emergency physician has access to at the time of initial presentation.
What were the failure modes? An AI that is more accurate on average but catastrophically wrong in specific high-stakes situations is not necessarily better than a human physician who is less accurate but knows when to escalate. The distribution of errors matters as much as the mean accuracy.
Why Diagnostic Accuracy ≠ Clinical Value
The gap between "more accurate" and "clinically useful" is one of the most consistently underestimated challenges in medical AI.
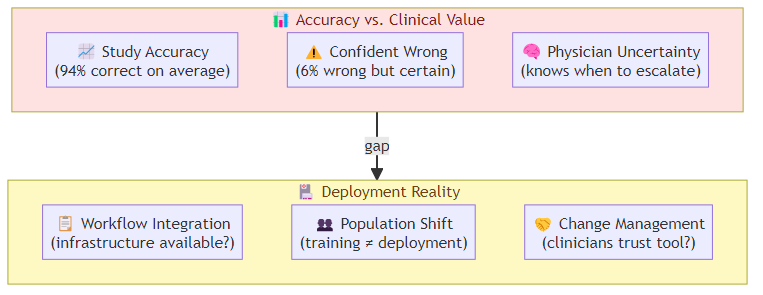
Accuracy metrics hide uncertainty poorly: human physicians are trained to express uncertainty and to know when they're uncertain. An AI diagnostic system that is 94% accurate might be producing confident wrong answers 6% of the time — which is very different from a physician who flags uncertainty when they're not sure. The communication of uncertainty, not just accuracy, is what determines clinical value.
Workflow integration determines real-world performance: a diagnostic AI that requires specific data formats, imaging sequences, or preprocessing steps will underperform in real emergency departments where that infrastructure isn't available. The study condition is not the deployment condition.
The "better than average physician" problem: if an AI system is more accurate than the average emergency physician, it is also more accurate than physicians below the average — which means it potentially raises the floor of care quality. But it is not better than the best physicians, and those physicians may be the ones who least need AI assistance. The distribution of who benefits matters enormously.
What Medical AI Does Well in Emergency Settings
Based on both published research and my deployment experience at Ai-Bharata, there are specific categories where medical AI has the strongest evidence base and clearest clinical value:
Radiology triage: AI systems that flag urgent findings in imaging (pneumonia on chest X-ray, intracranial hemorrhage on CT) are among the most mature medical AI applications. The workflow is well-defined, the error consequences are clear, and AI assistance can catch findings that a fatigued radiologist reviewing 80 studies in a shift might miss.
Electrocardiogram interpretation: for specific arrhythmia patterns, AI diagnostic accuracy exceeds cardiologist-level performance on defined tasks. The narrow domain, standardized input format, and clear error categories make this a favorable setting for AI.
Sepsis early warning: AI systems that monitor ICU patients and flag early sepsis signs have shown meaningful outcomes in deployment — earlier antibiotic initiation, reduced mortality. The continuous monitoring model plays to AI's strengths (consistent attention, pattern detection across multiple vital signs) in a way that point-in-time diagnosis does not.
Where Medical AI Still Struggles
Unstructured symptom presentation: emergency medicine is full of patients who present with vague, non-specific symptoms that could indicate dozens of conditions. The AI systems trained on structured data (lab results, imaging) perform poorly on the initial triage step where data is sparse and unstructured.
Multi-morbidity patients: elderly patients with multiple chronic conditions present with symptoms that don't fit the single-disease models that most AI systems are trained on. The interaction between conditions creates diagnostic complexity that exceeds the training distribution.
Contextual judgment: whether a diagnostic finding is clinically significant depends on context — the patient's age, comorbidities, medications, and social situation. AI systems trained on decontextualized data (imaging findings labeled by outcome without context) often lack the contextual judgment that experienced physicians develop over years.
The Deployment Gap: From Accuracy to Clinical Value
At Ai-Bharata, we learned this lesson repeatedly: the accuracy metrics we achieved in controlled studies didn't fully translate to deployment environments. The gap had several sources:
Population shift: our models were trained on datasets that over-represented urban, higher-SES populations. Rural and lower-SES populations had different disease prevalence patterns and presentation styles, which affected diagnostic accuracy in deployment.
Infrastructure variation: AI diagnostic tools that require high-resolution imaging or lab infrastructure performed differently in hospitals with older equipment or inconsistent lab processes.
Workflow disruption: physicians who were skeptical of AI diagnoses would override them even when the AI was correct, because the override workflow was easier than building trust in the tool. This wasn't a technology failure — it was a change management failure.
The lesson: medical AI deployment requires as much attention to organizational and workflow factors as to algorithmic accuracy. The teams that successfully deploy medical AI are the ones that treat it as a clinical change management project, not a technology deployment.
What This Means for the Harvard Study Headline
The Harvard study is a genuinely interesting result that adds to the evidence base for AI diagnostic capability. But it does not mean AI should replace emergency physicians, or that AI diagnostic tools are ready for deployment without careful integration design.
What it means: AI diagnostic systems are reaching accuracy levels that make them clinically relevant. The question for deployment is not whether they are accurate enough to be useful — in some categories, they are. The question is whether they are integrated into clinical workflows in ways that exploit their strengths, communicate their limitations, and augment rather than replace human clinical judgment.
The path from "more accurate than two human doctors in a study" to "clinically valuable in an emergency department" runs through workflow design, change management, and trust calibration. That's harder than building a more accurate model. It's also where the real work is.
Related posts: AI Agent Commerce — AI as an economic actor, parallel to AI as a diagnostic tool. Enterprise AI Capital Infusion — the funding landscape for AI deployments across domains.