The legal structure of AI is being written in real time, through a series of lawsuits, testimonies, and regulatory moves that will define what AI companies can and cannot do with the data they train on.
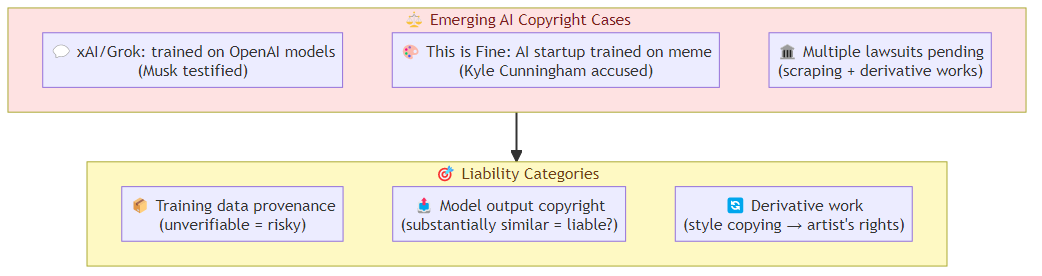
Two recent events crystallize the emerging battle lines. Elon Musk testified in the OpenAI trial that xAI trained Grok on OpenAI models — an admission that, if accurate, would constitute training on data that OpenAI may not have had rights to share. Meanwhile, Kyle Cunningham, creator of the viral "This is Fine" meme, accused an AI startup of training on his work without permission or compensation.
These aren't isolated incidents. They're the leading edge of a legal reckoning that every AI company will face: when training data becomes a liability rather than an asset.
The Training Data Liability Problem
The AI industry's foundational assumption is that training on publicly available data is legal. That assumption is now being stress-tested in courts around the world.
The argument for training on any available data rests on fair use doctrine — transformation of data into a model creates something new, not a derivative work. The counter-argument is that commercial training on copyrighted works without license or compensation is infringement, regardless of transformation.
The courts haven't resolved this. What's becoming clear is that the answer depends on specific facts: how the data was obtained, what transformation occurred, what the model does with the training, and whether the training data owner suffered economic harm.
This creates a specific problem for AI builders: the legal status of your training data is not a binary "legal" or "illegal." It's a risk assessment that depends on factors you may not fully understand and may not be able to fully audit.
The xAI Training Admission
Musk's testimony that xAI trained Grok on OpenAI models is significant beyond its immediate legal context. It reveals that even companies with enormous resources and legal sophistication make choices about training data that carry legal risk.
If xAI trained on OpenAI's outputs, they were potentially training on data that OpenAI itself may have had limited rights to use (e.g., data from paywalled sources, data subject to terms of service that prohibit scraping). The downstream liability for that training choice — if OpenAI's model is found to have been trained on infringing data — could extend to xAI.
This is a structural problem for the industry: if the upstream training data is legally contaminated, the contamination propagates downstream. An AI company that trains on outputs from a model that was itself trained on questionable data inherits those legal risks.
The practical implication for AI builders: the provenance of your training data matters as much as its quality. You need to understand not just what you trained on, but what your data sources trained on, to the extent that's knowable.
The "This is Fine" Case
The copyright claim from the "This is Fine" meme creator is different in character but similar in implication. This is a personal artist claim — not a large institution asserting rights, but an individual creator whose work was apparently used to train AI systems without consent or compensation.
The artist's claim has two components: the original work was used as training data, and the AI outputs are derivatives of that work. Both claims, if proven, would establish that the AI company trained on copyrighted work without license.
What makes this case particularly interesting is the cultural dimension. The "This is Fine" meme is one of the most recognizable images in internet culture. If its creator can successfully claim that AI training on his work constitutes infringement, the precedent applies to every image, text, and audio file that was scraped for training.
The Emerging Liability Categories
From the emerging case law, several distinct liability categories are taking shape:
Training data provenance liability: using training data whose legal status you can't fully verify. The defense is "we didn't know" but courts are increasingly skeptical of willful blindness arguments.
Model output copyright liability: when an AI model generates output that's substantially similar to copyrighted training data, the question is whether the output constitutes infringement. This is还没有定论,但早期案例表明,当模型输出与受版权保护的作品高度相似时,所有者可能有权要求赔偿。
Derivative work liability: the extent to which AI-generated content that was trained on specific works constitutes a derivative work subject to the original work's copyright. This is particularly relevant for style copying, where a model learns to generate in a specific artist's style.
What This Means for AI Builders
The practical implications for teams building AI systems:
Training data audit: understanding exactly what you trained on, where it came from, and what rights you have is no longer optional. The AI companies that can demonstrate clean training data provenance will be in a stronger legal position.
License negotiation: for commercial applications, the trend is toward licensed training data rather than scraped data. The cost is higher but the legal exposure is lower.
Output filtering: implementing content filters that detect and block outputs that are substantially similar to known copyrighted works reduces but doesn't eliminate output liability.
Terms of service awareness: many platforms explicitly prohibit scraping for AI training. The legal question is whether those prohibitions are enforceable and what liability attaches to violations.
Jurisdictional awareness: the legal landscape varies significantly by jurisdiction. Training that's legal in one country may be infringement in another. Multi-jurisdictional deployment requires jurisdictional analysis of training data.
The Industry Response
The AI industry's response to these legal pressures is predictable: lobbying for favorable legislation, building proprietary data assets that are legally cleaner, and technical approaches that reduce training data dependency (synthetic data, RLHF, constitutional AI).
The lobbying path faces real obstacles — the creative industries have strong political representation and clear economic interests in copyright protection. The proprietary data path favors companies with large data assets, which disadvantages newer entrants. The technical path is promising but incomplete.
The likely outcome: a partially licensed training data ecosystem where large AI companies negotiate deals with major content owners, while smaller players face more restricted access to high-quality training data. The legal uncertainty accelerates consolidation.
The Bottom Line
The AI copyright war is in its early innings. The cases that will establish the legal framework are still working through courts and regulatory processes. But the direction is clear: training data is becoming a liability, not just an asset.
The teams that build AI systems with clear training data provenance, appropriate licensing, and jurisdictional awareness will be better positioned than those that treat training data as a free resource to be exploited.
The era of "build fast and sort out the legal later" in AI training is ending. What's replacing it is a more mature, more legally rigorous approach to where AI models come from.
Related posts: AI Agent Security Hardening — the technical layer that protects AI systems from legal and security risks. Enterprise AI Capital Infusion — why the AI industry's investment patterns reflect legal risk awareness.