Cerebras Systems filed for its IPO this week — and the timing is anything but accidental.
The company has been OpenAI's most intimate compute partner, supplying the massive wafer-scale chips that power some of the most demanding training runs in the industry. For years, Cerebras operated in the shadows of Nvidia, with its unconventional architecture (a single wafer-scale chip the size of a dinner plate, rather than clusters of smaller dies) either dismissed as overengineering or celebrated as the only way to train frontier models efficiently.
Now it's going public. And the filing reveals something important about the AI compute layer: it's bifurcating into distinct markets with very different dynamics.
What Cerebras Is and Why It Matters
Cerebras built its reputation on a simple observation: the bottleneck in training large AI models isn't the芯片 count — it's the communication between chips. Traditional GPU clusters spend enormous energy and time moving data between thousands of separate processors. Cerebras solved this by building one chip that contains the entire model in a single piece of silicon — 850,000 cores on a 46,225 mm² die, roughly 100x larger than the largest Nvidia GPU.
The architecture is expensive to manufacture, limited in volume, and only makes sense for a narrow set of workloads: the largest training runs, the most compute-intensive foundation models. But for those workloads, it genuinely wins — faster training time, lower communication overhead, simpler programming model.
OpenAI has been Cerebras's anchor customer. Sam Altman's company has used Cerebras systems for training runs where the alternative would be thousands of Nvidia H100s arranged in complex distributed configurations. The partnership gave Cerebras real-world validation at the frontier — exactly the reference customers you want when going public.
The Bifurcating Compute Market
The Cerebras IPO filing confirms what the numbers have been suggesting: the AI compute market isn't monolithic. It splits into at least three layers with fundamentally different competitive dynamics:
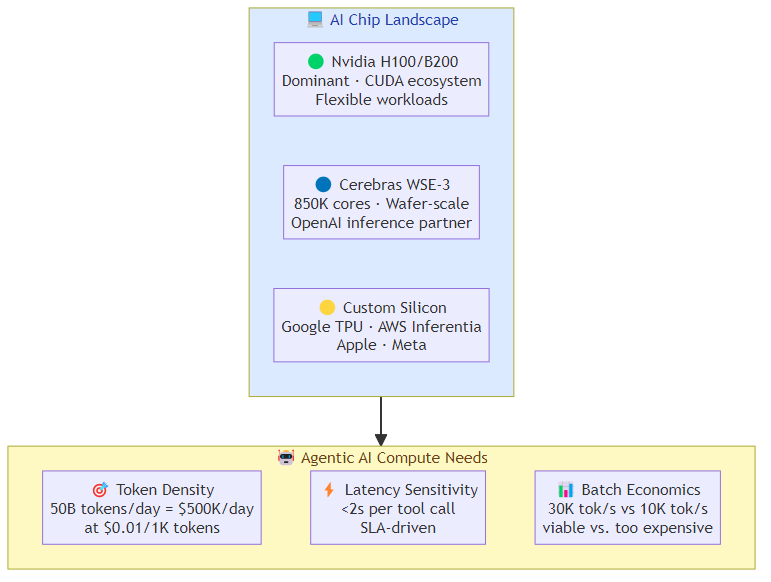
The commodity layer — standard GPU clusters for fine-tuning, inference, and fine-grained training. Dominated by Nvidia H100/H200 and increasingly AMD and custom silicon from hyperscalars. Margins compressed, competition intense, volume matters.
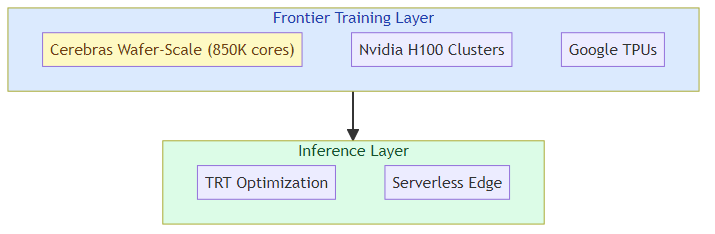
The frontier training layer — the compute for training foundation models from scratch or at massive scale. Dominated by Nvidia (A100/H100 clusters) but with real alternatives from Cerebras, Graphcore (now owned by Microsoft), and custom silicon from Google (TPU), Amazon (Trainium), and Meta. This layer values raw throughput for specific model architectures over general utility.
The custom silicon layer — purpose-built AI accelerators designed for specific model architectures or inference patterns. Apple's Neural Engine, Google's TPU v5, Amazon's Trainium and Inferentia, Microsoft's Maia. These chips don't compete on general compute — they compete on efficiency for specific workloads that their parent companies care most about.
Cerebras lives in layer two — the frontier training layer — and the IPO filing shows it's trying to expand into layer three: inference acceleration at scale, where its wafer-scale architecture has potential advantages for serving very large models efficiently.
What the IPO Reveals About AI Economics
The filing gives us rare visibility into the financial structure of a frontier AI compute company. The numbers that matter:
Revenue concentration risk: OpenAI as anchor customer means Cerebras's revenue is heavily tied to one organization's training schedule. When OpenAI is in a heavy training phase, Cerebras benefits. When OpenAI shifts to inference-heavy operations or changes its architecture strategy, Cerebras feels it.
Gross margin profile: Wafer-scale chips have extremely high manufacturing cost but potentially high margins at scale — the same silicon that costs $300,000 to produce might be sold for $2M+ per system. The question is whether Cerebras can build enough volume to make the manufacturing economics work.
The inference opportunity: The filing signals Cerebras is positioning for inference as much as training. Running trained frontier models — the kind that power ChatGPT-scale applications — requires different but equally demanding compute. Cerebras's architecture may have advantages for inference on very large models that can't be efficiently distributed across traditional GPU clusters.
The Hyperscalar Custom Silicon Threat
Here's where the investment case gets complicated: the hyperscalars are all building their own AI chips, and they're moving fast.
Google's TPUs are already in their fifth generation and power a significant portion of the company's own AI training. Amazon's Trainium is now in its second generation, competing directly with Nvidia for training workloads. Microsoft's Maia chip is being deployed for inference. Meta's MTIA is targeting recommendation system inference.
None of these custom chips compete directly with Cerebras at the frontier training layer — yet. But as frontier model architectures stabilize and the industry learns what compute patterns dominate, custom silicon will expand into more workloads.
The question for Cerebras isn't just whether it can win on performance — it's whether it can stay ahead of the custom silicon curve while building the volume and customer diversity to survive if custom chips eat into GPU replacement demand.
What the IPO Means for the AI Infrastructure Market
The Cerebras IPO is a data point in a larger pattern: AI infrastructure is becoming a legitimate public market category. We've moved from "AI chips are interesting" to "there's a path to liquidity for AI infrastructure companies that can demonstrate real revenue."
Three implications:
More infrastructure IPOs will follow: If Cerebras succeeds in going public, it validates the market for other AI infrastructure companies. Lambda Labs, CoreWeave, and other GPU cloud providers have been discussed as potential public market candidates. The Cerebras filing sets a precedent for how these companies present themselves to public market investors.
The OpenAI relationship becomes a double-edged sword: Cerebras's close ties to OpenAI were an asset when OpenAI was the undisputed leader in AI. Now that Anthropic is raising at $900B+ valuations and Google and Meta are spending comparable amounts on training, the relationship with a single customer creates narrative risk. The filing will have to explain how it diversifies.
Inference economics reshape the story: The transition from training to inference as the dominant compute workload changes the investment thesis. Inference requires different architectures and different economics. Cerebras positioning itself as both a training and inference company is the right move — but it needs to show investors it can win in inference against Nvidia's formidable TensorRT ecosystem.
For AI Builders
If you're building AI systems that depend on frontier training or large-model inference, Cerebras going public has a practical implication: it signals that the compute market is maturing and that multiple competing architectures will be available rather than just Nvidia.
Watch the filing's customer concentration disclosures — they'll tell you how diversified Cerebras's revenue really is beyond OpenAI. Watch whether they disclose any anchor inference customers — that's the growth story that matters.
The compute layer of AI infrastructure is becoming a category. Cerebras is the first pure-play frontier compute company to test public market appetite for it.
Related posts: Sierra's $950M Raise — the enterprise AI agent company capturing value at the application layer. Anthropic + OpenAI Enterprise JVs — the AI labs' counter-move into enterprise services.