
BrowserArena: We Finally Have a Live Benchmark for Web Agents (And the Results Hurt)
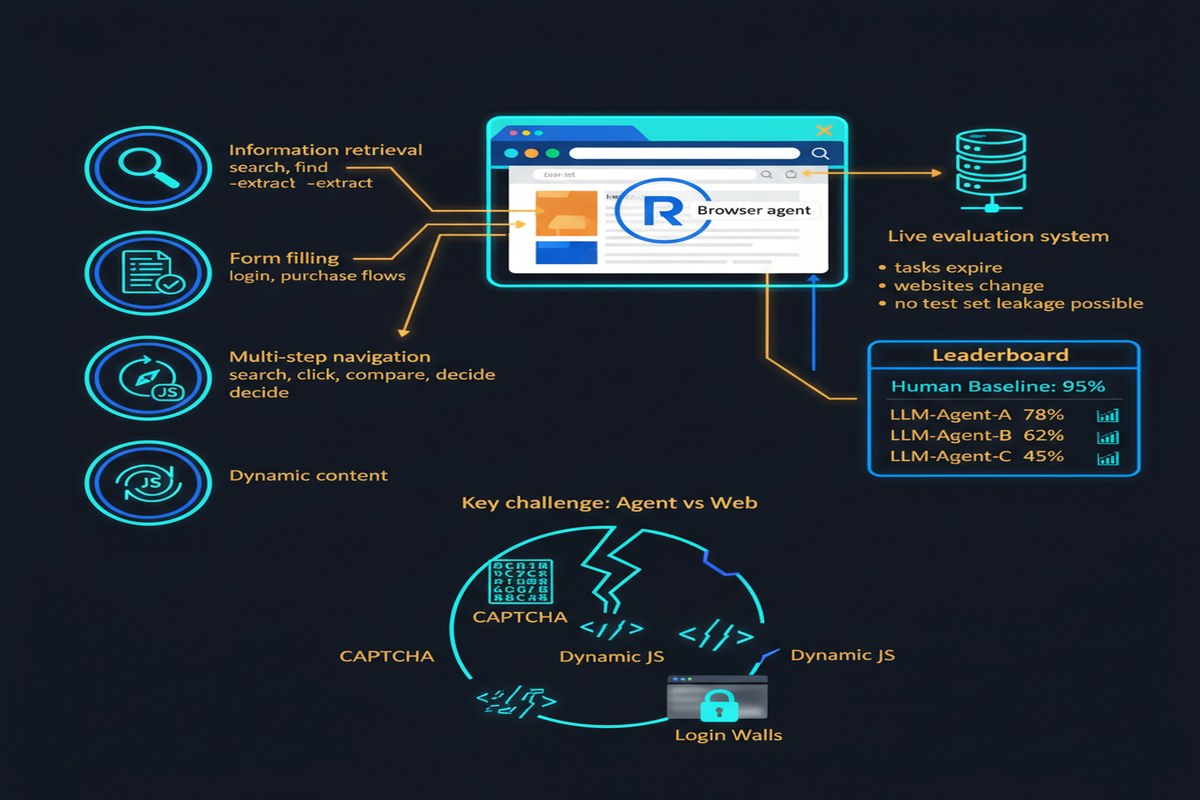
Web agents — LLMs that can browse the internet, fill forms, click buttons, and complete multi-step web tasks — have been one of the most hyped capabilities in the AI space. Every major lab has one. Every startup promises one. And every benchmark paper shows impressive numbers on carefully curated test sets.
Then you try to use them on an actual website and they fall apart.
BrowserArena (arXiv: 2510.02418, Oct 2025) is the first live evaluation platform for web agents that takes user-submitted tasks from the real world, runs them against competing LLMs using the BrowserUse library, and continuously updates leaderboard results. It's exactly what the field needed — and what the field's inflated benchmarks were actively hiding.
The Problem With Current Web Agent Benchmarks
WebArena, Mind2Web, VisualWebArena — these static benchmarks have been the measuring stick for web agents. They're carefully constructed, reproducible, and peer-reviewed. They're also fundamentally limited:
Static benchmarks freeze the web. They capture a snapshot of specific websites at a specific time. Websites change. Buttons move. Login flows update. A model that achieves 85% on WebArena may crash on the live version of the same site 6 months later.
Task selection bias. Static benchmarks select tasks that are amenable to automated evaluation. Real-world web tasks are messy, ambiguous, and often require judgment calls that automated evaluators miss.
Leaderboard gaming. When researchers know the benchmark, they can optimize for it specifically — through data contamination, task-specific prompting tricks, or cherry-picking architectures. The benchmark becomes a solved exam rather than a measure of capability.
BrowserArena tries to fix all of this.
How BrowserArena Works
sequenceDiagram
participant U as Real User
participant P as BrowserArena Platform
participant A1 as LLM Agent 1
participant A2 as LLM Agent 2
participant W as Live Website
U->>P: Submit real-world task
P->>A1: Send task to Agent 1
P->>A2: Send task to Agent 2
A1->>W: Execute task via BrowserUse
A2->>W: Execute task via BrowserUse
W->>A1: Page state, DOM, screenshots
W->>A2: Page state, DOM, screenshots
A1->>P: Task result
A2->>P: Task result
P->>U: Results + side-by-side comparison
U->>P: Human preference vote
P->>P: Update ELO rankings
Users submit task descriptions in natural language: "Find the cheapest flight from Bengaluru to London departing next Friday," "Find and download the 2024 annual report for TCS," "Create a new GitHub issue in the BrowserUse repo with title 'test issue'."
Two randomly-selected LLMs attempt the task using BrowserUse, a library that provides standardized browser control primitives. Users observe the agents' actions and vote on which performed better. ELO rankings update continuously.
The live, user-submitted nature means:
- Tasks come from real needs, not researcher imaginations
- Websites are always current
- There's no way to overfit to the benchmark (it's always changing)
- Human preference drives evaluation, not automated metrics that may not capture what actually matters
What the Results Show
The leaderboard reveals uncomfortable truths about the state of web agents:
The gap between frontier and open models is real and large. Claude, GPT-4o, and Gemini Ultra perform significantly better than open-weight models on actual user tasks. The gap is larger than static benchmarks suggest, because live tasks expose failure modes that curated benchmarks don't exercise.
Multi-hop reasoning kills agents. Tasks that require combining information across multiple pages — "find the CEO of Company X, then check their LinkedIn for their previous employer, then look up that company's annual revenue" — have dramatically lower success rates than single-page tasks. Current agents struggle to maintain coherent state across long browsing sequences.
Dark patterns are adversarial inputs. Sites designed with dark patterns (misleading buttons, buried opt-outs, deceptive confirmation flows) cause agent failure rates to spike. This was studied in a companion paper (arXiv: 2510.18113) — agents are disproportionately vulnerable to deceptive UI elements designed to exploit human cognitive biases, because those same biases exist in their training data.
Authentication is a hard wall. Any task requiring login drops success rates substantially. Session management, 2FA, and security challenges create barriers that current agents handle poorly.
bar
title Web Agent Task Success Rate by Category (approximate)
x-axis [Single-page, Multi-hop, Auth Required, Dark Patterns]
y-axis 0 --> 100
"Frontier Models" : [72, 41, 28, 19]
"Open Models" : [48, 23, 12, 8]
Approximate figures based on BrowserArena observations
The Architecture of Failure
BrowserArena's qualitative analysis identifies recurring failure patterns:
Context exhaustion: Long web sessions push agents past their effective context window. Earlier steps are forgotten, leading to repetitive actions or contradictory decisions.
Grounding errors: Agents correctly identify what they need to click but incorrectly identify where on the page. Even small coordinate errors cause cascading failures.
Premature task completion: Agents frequently declare success before actually completing the task — a form of hallucination about their own actions.
Recovery from errors: When agents make a mistake (navigate to the wrong page, fill a form incorrectly), they often fail to detect and recover from the error. Human web users are skilled at error recovery; agents are brittle.
Why This Matters for Enterprise AI
Enterprise automation is the primary commercial application for web agents. Automating invoice processing, vendor portal interactions, data extraction from legacy web systems — these are tasks that don't have APIs, that require navigating real web interfaces at scale.
BrowserArena's results suggest the technology is further from enterprise-ready than the hype suggests. The benchmark's live nature also provides continuous measurement as models improve — something the industry desperately needs to track real progress.
The dark pattern vulnerability finding is especially important for trust: if an agent is given financial authority and can be manipulated by a malicious website to take unintended actions, that's not a minor UX issue — it's a security vulnerability.
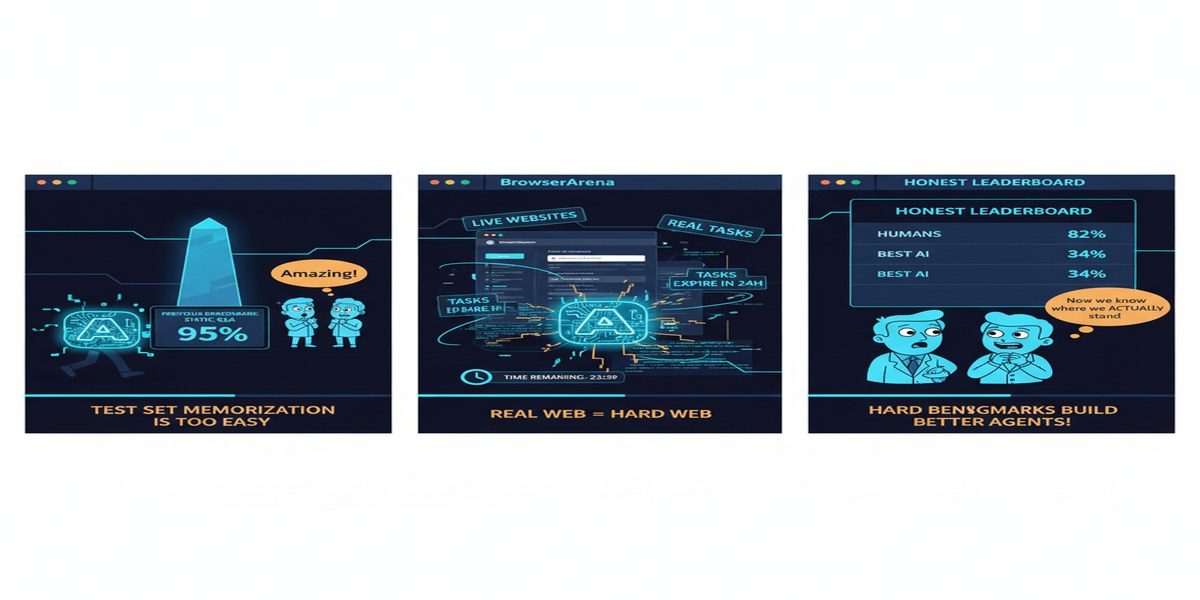
My Take
BrowserArena is the evaluation infrastructure the web agent field has needed for two years. The live, user-submitted evaluation model is clearly the right approach for measuring real-world capability. I hope it becomes the standard reference benchmark and displaces the static alternatives that have been flattering agents with curated tasks.
The results should humble both researchers and product teams. Web agents are genuinely useful for narrow, well-defined tasks on well-behaved websites. They are not yet reliable for the open-ended automation that product demos suggest.
The path forward is clear from the failure modes: better state management across long sessions, explicit error detection and recovery loops, and adversarial robustness training against dark pattern UIs. None of these are unsolvable — they're engineering problems with clear directions.
What I want to see next: BrowserArena-style evaluation infrastructure for more specialized domains — medical portals, government systems, enterprise SaaS. The capability gaps will be even starker there, and the stakes are higher.
Benchmark honestly. Deploy carefully. The web is harder than it looks.
Paper: "BrowserArena: Evaluating LLM Agents on Real-World Web Navigation Tasks", arXiv: 2510.02418, Oct 2025.


