
Paper: Understanding and Enhancing Mamba-Transformer Hybrids arXiv: 2510.26912 | October 2025 Also: Jamba at ICLR 2025, and various hybrid explorations throughout 2025
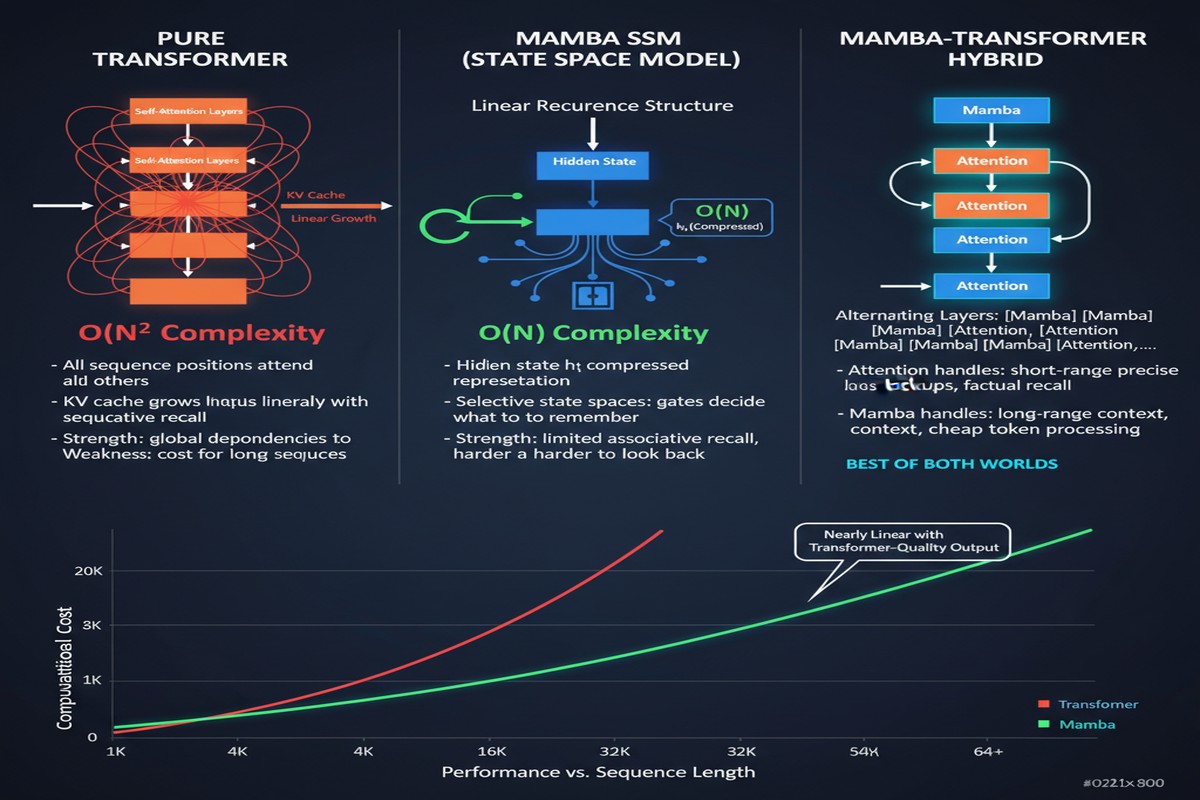
The transformer architecture has dominated language modeling since 2017. It is powerful, well-understood, and backed by an industrial ecosystem of tooling, optimization, and expertise. It also has a fundamental problem: self-attention scales quadratically in memory and compute with sequence length. As context windows grow — and they must grow for agents to be useful — the quadratic cost becomes a wall.
State Space Models (SSMs), particularly Mamba, proposed an alternative: linear-time sequence modeling using selective state spaces. Mamba's selective scan mechanism is genuinely clever — it learns to filter the input stream, keeping only what matters for the current state. In pure SSM models, you get O(n) complexity instead of O(n²), which at 100K tokens means roughly 100x less memory for attention computation.
The problem: SSMs are not as good at in-context retrieval. The quadratic attention mechanism that makes transformers expensive also makes them very good at looking back at arbitrary positions in a long context — a capability that matters enormously for retrieval tasks, key-value lookups, and many reasoning patterns.
So: transformer is good at retrieval, expensive at scale. SSM is cheap at scale, weaker at retrieval. The natural question is whether a hybrid can get the best of both.
The answer, based on the papers from 2025, is: yes, with caveats.
What Hybrid Architectures Look Like
There are two primary ways to hybridize transformers and SSMs:
flowchart TD
subgraph "Sequential Hybrid"
A1[Token] --> B1[Mamba Block]
B1 --> C1[Mamba Block]
C1 --> D1[Attention Block]
D1 --> E1[Mamba Block]
E1 --> F1[Attention Block]
F1 --> G1[Output]
end
subgraph "Parallel Hybrid"
A2[Token] --> B2[Mamba Branch]
A2 --> C2[Attention Branch]
B2 --> D2[Aggregate]
C2 --> D2
D2 --> E2[Output]
end
subgraph "Design Choices"
H[Ratio: SSM to Attention layers]
I[Placement: Where are attention layers?]
J[Coupling: How outputs are combined]
end
Sequential hybrids interleave Mamba and attention layers in sequence. The ratio and placement of attention layers is a design choice — Jamba, for example, uses attention every 8 Mamba layers (roughly 12.5% attention layers). The rationale is that occasional full attention provides the retrieval capability the SSM needs, while the Mamba layers handle the bulk of sequence processing at linear cost.
Parallel hybrids run Mamba and attention branches on the same input simultaneously and aggregate their outputs. This is more parameter-expensive but allows the model to learn which pathway is more useful for each layer and task type.
The paper finds that the SSM-to-attention ratio is a critical hyperparameter. Too few attention layers and retrieval degrades. Too many and you lose the efficiency gains of SSM. For the models studied, a 7:1 Mamba-to-attention ratio appears to be near-optimal on the compute-quality frontier.
What Jamba Showed
Jamba (presented at ICLR 2025) is the most visible hybrid model of the year. It combines Mamba and attention in a 7:1 ratio with a Mixture-of-Experts structure, totaling 52B parameters with 12B active per token.
Key results:
- Matches Llama-3-70B on most benchmarks while using significantly less KV cache memory
- Processes 256K context on a single 80GB GPU (versus Llama-3's ~32K limit at the same GPU memory)
- Inference throughput significantly higher than equivalent-size dense transformers at long contexts
The throughput advantage is the story. For long-context inference serving, Jamba's hybrid approach allows larger batches at the same memory budget, which translates directly to lower serving cost per request.
Understanding When Each Architecture Wins
The 2510.26912 paper contributes a more systematic analysis than previous hybrid work. It characterizes which task types favor SSMs, which favor attention, and which are roughly equal:
| Task Type | SSM Advantage | Attention Advantage |
|---|---|---|
| Next-token prediction | Moderate | Baseline |
| Long-range retrieval | Weak | Strong |
| Local pattern recognition | Strong | Moderate |
| In-context learning | Weak | Strong |
| Long-context summarization | Moderate | Moderate |
The implication is clear: for workloads dominated by local pattern recognition and generation, SSM-heavy hybrids are preferable. For workloads dominated by in-context learning and retrieval, more attention layers are needed.
This points toward workload-adaptive architecture selection as a future direction — models that dynamically adjust their SSM/attention ratio based on the incoming task type. This is technically challenging but theoretically principled.
Why This Matters
1. Long-context efficiency is the frontier challenge. As models become agents operating on large codebases, long documents, and multi-turn histories, context length matters more than it ever did for chatbots. Hybrid architectures address this directly by making long-context processing economically viable.
2. The Mamba ecosystem is maturing. Hunyuan-A13B (from Tencent) used Mamba-like layers in a production hybrid architecture, validating that these approaches work outside research settings. We are past the "interesting academic result" phase.
3. Hybrids may be the architecture for the next generation of open models. Llama's dense attention architecture is hitting memory constraints at long contexts. MoE models address parameter efficiency but not attention complexity. SSM-Transformer hybrids address attention complexity directly. I expect the next wave of competitive open models to explore this space heavily.
4. The tooling gap is closing. Early SSM implementations were poorly supported by production inference frameworks. FlashLinearAttention and other libraries now provide efficient CUDA kernels for SSM inference, making hybrid models practical to serve at production scale.
My Take
I have been watching the SSM space since the original Mamba paper (late 2023), and 2025 is the year it became serious. Jamba at ICLR, Hunyuan deploying it at scale, and the systematic analysis papers are all evidence that hybrid architectures are transitioning from research curiosity to viable production option.
My honest assessment: pure SSMs are not going to replace transformers, and hybrids are the right synthesis. Pure SSMs sacrifice too much retrieval capability for general-purpose LLMs. But spending 100% of your architecture on quadratic attention is increasingly indefensible as context windows grow.
The 7:1 Mamba-to-attention ratio that multiple papers converge on is a useful rule of thumb, but I expect this to be task- and context-length-dependent. The future is probably adaptive hybrids that adjust this ratio dynamically — similar to how MoE selects experts adaptively.
What I find most interesting is the memory angle. For a model serving 10,000 concurrent long-context requests, the KV cache size is directly proportional to the number of attention layers. Every Mamba layer you substitute reduces KV cache by that layer's contribution. At 7:1 ratio, you're eliminating 87.5% of your KV cache memory, which is transformative for serving economics.
The caution: the tooling for training hybrid models efficiently is still less mature than for pure transformers. Teams adopting this architecture need to invest in training infrastructure, not just inference. For organizations without significant ML infrastructure teams, sticking with transformer-based models from established labs is probably still the right call. But for organizations building the next generation of models, ignoring hybrid architectures is becoming harder to justify.

arXiv:2510.26912 — read the full paper at arxiv.org/abs/2510.26912 Jamba: arxiv.org/abs/2403.19887


