
NVIDIA has been quietly but systematically expanding its footprint from GPU manufacturer to full-stack AI infrastructure company. The latest move in this strategy is the Physical AI Data Factory Blueprint — an open reference architecture that unifies and automates the generation, augmentation, and evaluation of training data for robotics, vision AI agents, and autonomous vehicles. It is one of the most significant announcements NVIDIA has made in the physical AI space, and its implications extend well beyond the immediate technical scope.
To understand why this matters, you need to appreciate the bottleneck it addresses. Training a robot to manipulate objects in a warehouse, or a vehicle to navigate urban streets, requires enormous quantities of labeled data covering an impossibly wide range of scenarios. Collecting this data in the real world is slow, expensive, and dangerous. Generating it synthetically is faster and safer, but has historically been fragmented across dozens of tools and workflows, each requiring specialized expertise. NVIDIA's blueprint is an attempt to standardize and streamline this entire pipeline.
What the Blueprint Actually Is
The Physical AI Data Factory Blueprint is not a single product. It is a reference architecture — a set of integrated tools, APIs, and workflows that organizations can deploy to create a continuous pipeline of synthetic training data for physical AI systems. The architecture spans several stages.
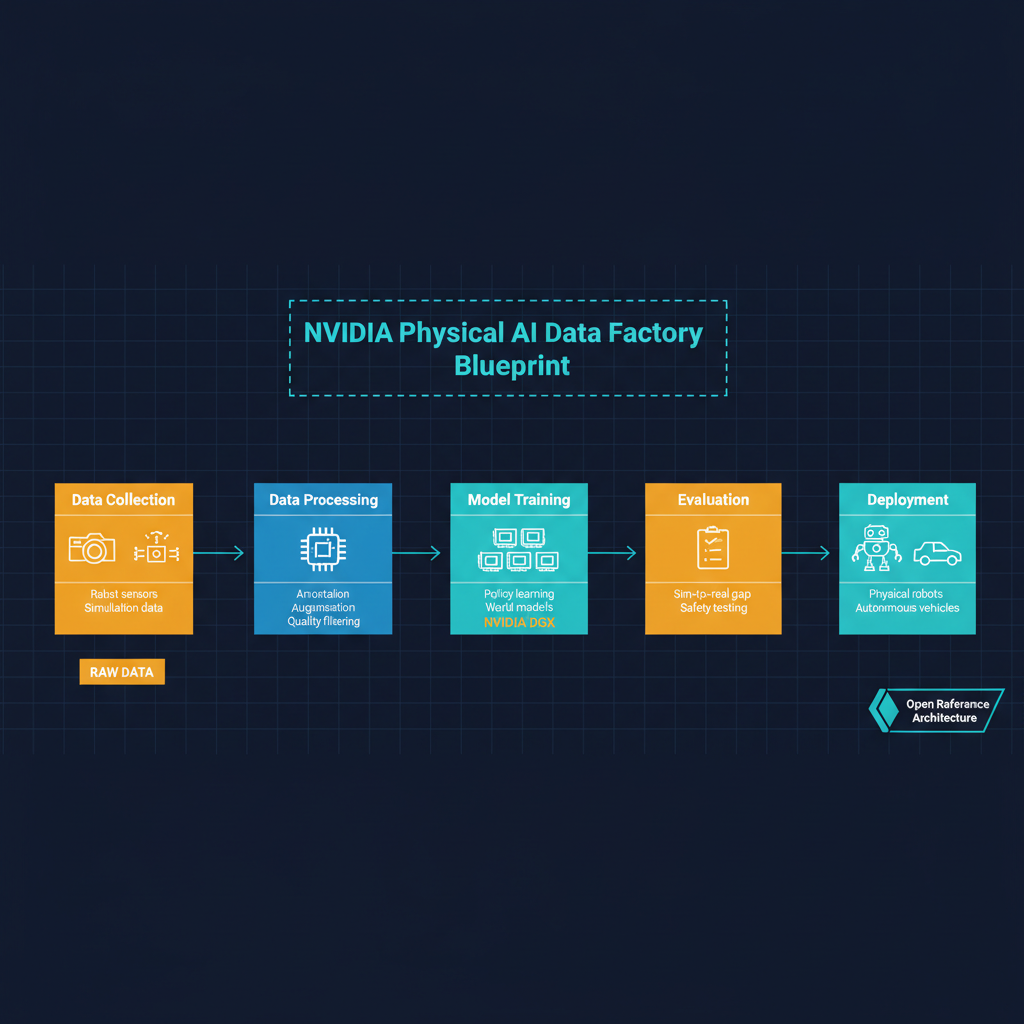
Data generation is handled through NVIDIA's Omniverse platform, which can produce photorealistic synthetic environments — warehouses, roads, surgical theaters, factory floors — populated with physically accurate objects, lighting, and materials. These environments can be parameterized and varied programmatically: change the lighting conditions, swap out object textures, adjust camera angles, introduce occlusions, all through API calls rather than manual scene construction.
Data augmentation applies systematic transformations to both real and synthetic data: domain randomization, sensor noise injection, viewpoint perturbation, and physics-based distortions that make trained models more robust to real-world conditions. This is not new in concept — domain randomization has been a standard technique in sim-to-real transfer for years — but NVIDIA's contribution is integrating it into a unified pipeline rather than leaving it as a research prototype that each team must reimplement.
Evaluation and validation complete the loop. The blueprint includes tooling for measuring model performance against held-out scenarios, identifying failure modes, and automatically generating targeted training data to address weaknesses. This closed-loop approach — generate, train, evaluate, regenerate — is where the real efficiency gains come from.
The Data Problem in Physical AI
The significance of this announcement becomes clearer when you consider the scale of the data problem in physical AI. Language models can be trained on the internet — trillions of tokens of text that humans have conveniently generated over the past few decades. Physical AI has no such windfall. Every training scenario for a robot arm, every driving scenario for an autonomous vehicle, every visual inspection scenario for a manufacturing quality system must be either painstakingly collected in the real world or carefully constructed in simulation.
Real-world data collection for robotics is measured in hours per scenario, not tokens per second. A single autonomous vehicle driving program might generate petabytes of sensor data per year, but the vast majority of that data covers routine scenarios. The edge cases — unusual weather, unexpected obstacles, novel failure modes — are by definition rare and difficult to capture systematically. Yet these edge cases are precisely what determine whether a system is safe enough to deploy.
Synthetic data generation has been the industry's answer to this bottleneck, but until now it has required substantial in-house expertise. Companies like Waymo, Tesla, and Boston Dynamics have built proprietary simulation and data generation pipelines at enormous cost. Smaller robotics companies, academic labs, and startups have been largely locked out of this approach by the engineering investment required.
NVIDIA's blueprint democratizes this capability. By providing an open reference architecture built on Omniverse, NVIDIA is making it possible for a mid-size robotics company to stand up a synthetic data pipeline in weeks rather than building one from scratch over months or years. The cost and time reduction is not incremental — it is potentially an order of magnitude.
NVIDIA's Full-Stack Ambition
This announcement fits into a pattern that has been evident for several years but is now unmistakable: NVIDIA is building itself into a full-stack AI infrastructure company. The progression has been methodical.
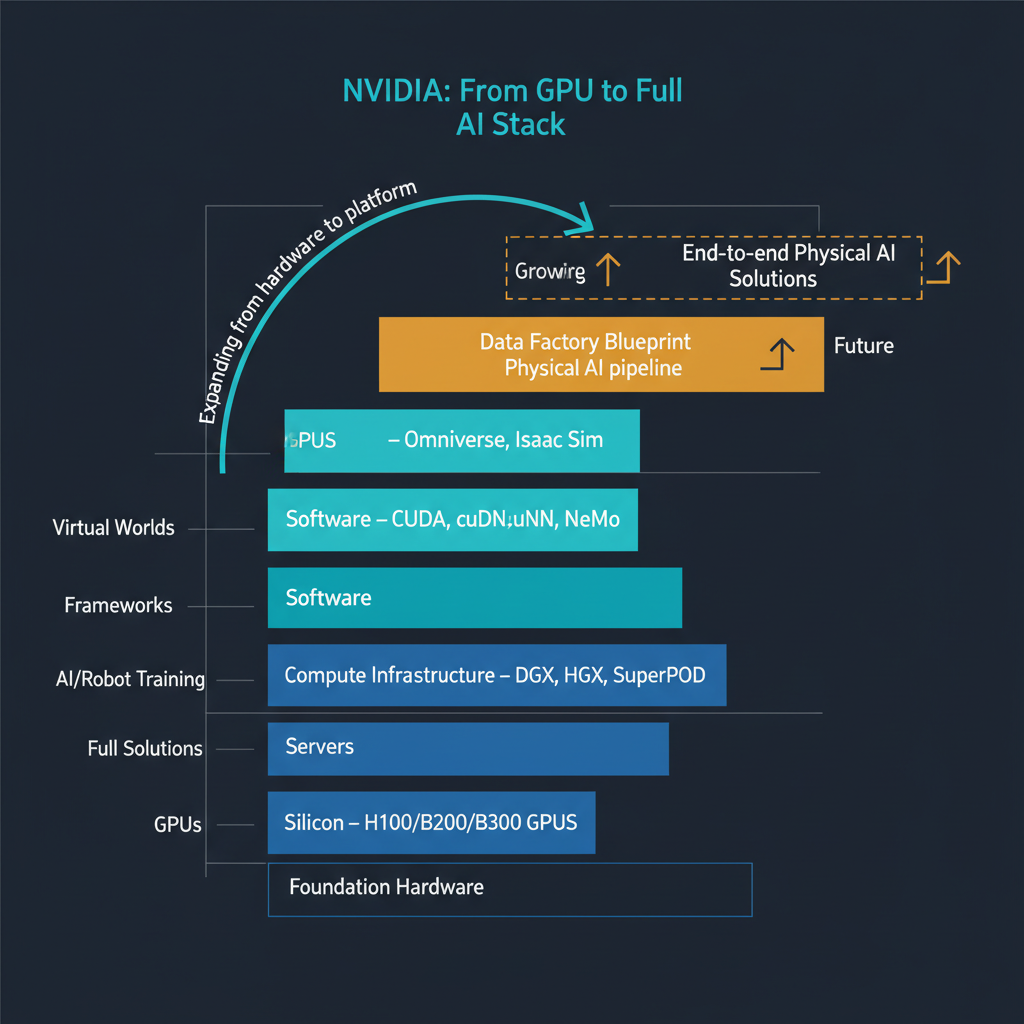
It started with GPUs — the fundamental compute layer. Then came CUDA and the software ecosystem that made those GPUs programmable for AI workloads. Then networking with Mellanox/InfiniBand for multi-GPU and multi-node training. Then DGX systems for turnkey training infrastructure. Then Omniverse for simulation and digital twins. Then Isaac for robotics development. Now the Data Factory Blueprint for training data generation.
Each layer moves NVIDIA further up the stack and deeper into its customers' workflows. The strategic logic is clear: the more of the AI development pipeline that runs on NVIDIA infrastructure and tooling, the stronger NVIDIA's competitive position becomes, regardless of what happens at the model layer. Whether the winning robotics models come from OpenAI, Google DeepMind, or a startup nobody has heard of yet, NVIDIA wants them all trained on NVIDIA infrastructure using NVIDIA tools processing data generated by NVIDIA pipelines.
This is a platform strategy, and it is executed with a sophistication that I find genuinely impressive. By making the blueprint open, NVIDIA avoids the perception of vendor lock-in while still ensuring that the most natural implementation path runs through NVIDIA hardware and software. Open standards that happen to work best on your proprietary hardware are a powerful competitive tool.
Implications for the Robotics Industry
For the robotics industry specifically, the Data Factory Blueprint addresses a timing problem. We are at an inflection point where foundation models for robotics — large models pretrained on diverse manipulation and navigation data, then fine-tuned for specific tasks — are becoming viable. Google DeepMind's RT-2, the open-source efforts around Open X-Embodiment, and several stealth-mode startups are all pursuing this approach.
But foundation models for robotics need massive, diverse training datasets that no single organization can collect on its own. A standardized, open architecture for generating and sharing synthetic training data could accelerate the development of robotics foundation models in the same way that Common Crawl and The Pile accelerated language model development.
I think this is the most important long-term implication of NVIDIA's announcement. The Data Factory Blueprint is not just a tool for individual companies to generate their own training data — it is potentially the infrastructure for a shared data ecosystem that makes physical AI foundation models practical.
What to Watch For
Several questions will determine how impactful this blueprint ultimately becomes. First, adoption: will major robotics companies actually standardize on this architecture, or will they continue to build proprietary pipelines? The answer likely depends on how much NVIDIA invests in making the blueprint genuinely production-ready versus leaving it as a reference implementation that requires significant customization.
Second, sim-to-real transfer quality: synthetic data is only valuable if models trained on it perform well in the real world. The gap between simulation and reality — the so-called "reality gap" — has been narrowing but remains significant for many tasks. NVIDIA's Omniverse produces impressive visuals, but visual fidelity is only one dimension of physical realism. Physics simulation accuracy, sensor noise modeling, and material property representation all matter.
Third, competitive response: how will other simulation platforms — Unity, Unreal Engine, MuJoCo, Isaac Gym's competitors — respond? NVIDIA's blueprint advantage is integration with its own hardware ecosystem, but the simulation market is contested.
My assessment is that NVIDIA's move into physical AI training infrastructure is strategically sound and technically credible. The company's track record of building platform-level tools that become industry standard — CUDA being the canonical example — suggests this is not a product that will be abandoned after one press cycle. Physical AI is the next major frontier for AI deployment, and NVIDIA is positioning itself to be as central to that frontier as it has been to the language model era. That positioning deserves attention from anyone building in the robotics, autonomous systems, or industrial AI space.


