When Morgan Stanley's research team publishes a note telling institutional investors that AI progress is about to "shock" them, it is worth pausing to consider what they know that the rest of us might be underweighting. The firm's latest analysis, drawing on conversations with executives at leading AI labs, paints a picture that is equal parts exhilarating and disorienting: a roughly 10x increase in compute is yielding a doubling in model intelligence, and the compute buildout currently underway means several such doublings are already in the pipeline.
This is not a speculative blog post from an anonymous researcher. This is a major Wall Street institution telling its clients to prepare for a capability discontinuity. That framing alone is significant, because financial analysts tend toward conservatism when their reputations are on the line.
The 10x Compute Relationship
The central empirical claim is one that Elon Musk has articulated publicly and that multiple lab executives have corroborated privately: for current frontier architectures, roughly a 10x increase in training compute produces an approximate doubling in what we might loosely call "model intelligence" — performance across reasoning, knowledge recall, instruction following, and creative generation.
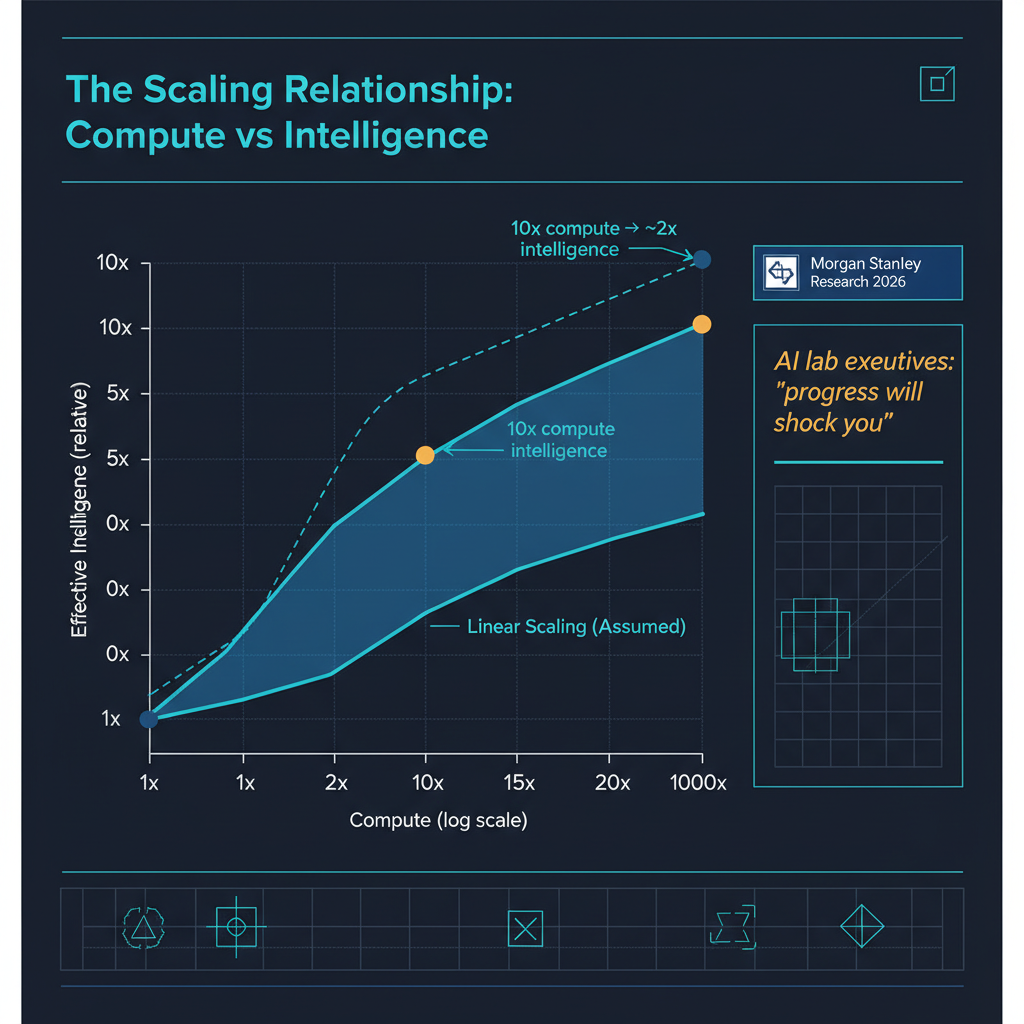
This is a restatement of scaling laws, but with a crucial practical implication that Morgan Stanley's note drives home. The compute infrastructure being deployed right now — the billion-dollar data center expansions from Microsoft, Google, Amazon, and xAI — represents not a marginal increase but a multi-order-of-magnitude jump in available training compute over the next 18 to 24 months. If the 10x-to-2x relationship holds, that translates to several successive doublings in model capability arriving in rapid succession.
I want to be careful here, because "model intelligence" is a loose and contested concept. But even if you operationalize it narrowly — say, performance on graduate-level reasoning benchmarks, or success rate on novel multi-step tasks — the empirical trend is clear. GPT-4 was a meaningful jump over GPT-3.5, which was a meaningful jump over GPT-3. Each generation has roughly corresponded to an order-of-magnitude increase in effective training compute.
Transformers Executing Programs in Inference
Perhaps the most technically striking claim in the Morgan Stanley analysis concerns architectural advances that are complementing raw scaling. Specifically, recent research has demonstrated that transformer models can now execute programs inside their own inference loop — effectively running compiled algorithms as part of the forward pass rather than relying purely on learned statistical patterns.
This matters because it addresses one of the oldest criticisms of neural language models: that they are sophisticated pattern matchers incapable of genuine algorithmic reasoning. The emerging work on integrating learned representations with compiled algorithms suggests a path toward models that combine the flexibility and generalization of neural networks with the precision and reliability of traditional programs.
The practical implications are significant. Consider a model that encounters a novel mathematical problem during inference. Rather than relying solely on patterns learned during training, it could invoke a symbolic computation routine within its own inference process, verify its reasoning steps algorithmically, and return a result with a qualitatively different kind of reliability than pure neural generation provides.
Several research groups are working on variants of this idea. The core technical insight is that attention mechanisms can be configured to simulate program execution, and that these execution pathways can be learned alongside conventional language modeling objectives. We are in the early stages, but the direction is clear: the line between neural networks and traditional software is blurring from both sides.
Scaling Laws vs. Architectural Innovation
This brings us to a debate that has been simmering in the research community for over a year: are the next major capability gains going to come from scaling existing architectures further, or from architectural innovation that changes the fundamental compute-capability relationship?
The honest answer is both, and the Morgan Stanley analysis reflects this. The scaling law proponents — and they have strong empirical support — argue that we have not yet reached the ceiling of what dense and mixture-of-experts transformers can do when trained with sufficient compute on sufficient data. The infrastructure investments currently underway are premised on this bet.
The architectural innovation camp points to results like the program-execution-in-inference work, advances in state space models, better attention mechanisms, and novel training objectives that seem to shift the scaling curve itself rather than simply moving further along it. If a new architecture achieves the same performance as a standard transformer but with 10x less compute, that is economically equivalent to a 10x compute increase — but achieved through engineering rather than capital expenditure.
My read is that we are entering a period where both forces compound. The massive compute buildout will power both conventional scaling and the training of architecturally novel systems. The labs that combine scaling discipline with architectural creativity will pull ahead of those that rely on brute force alone.
What the "Shock" Actually Looks Like
When AI lab executives tell Morgan Stanley's analysts that progress will "shock" investors, what are they concretely pointing to? Based on public statements, research publications, and the trajectory of recent releases, I think the shock will manifest in several ways.
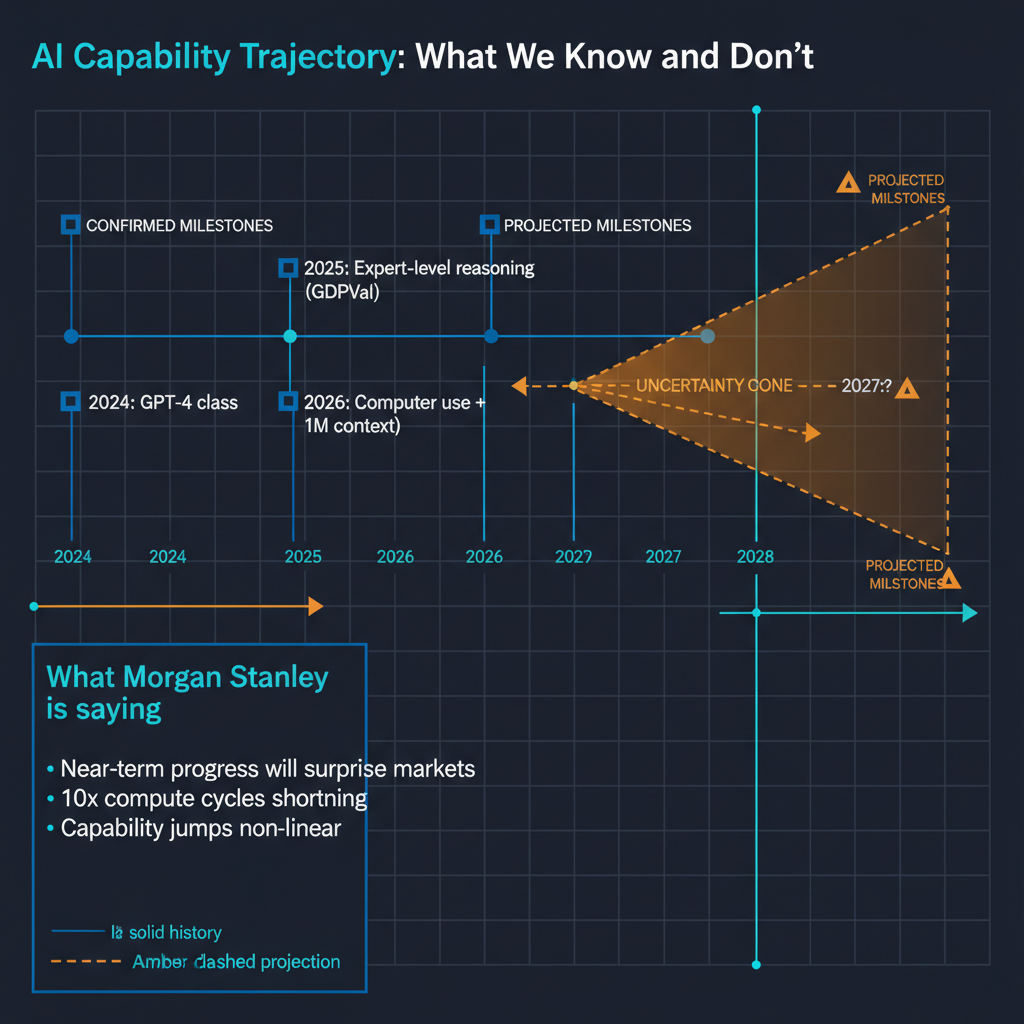
First, the gap between current frontier models and the next generation will be larger than the gap between any two successive generations we have seen so far. This is simply the mathematical consequence of the compute relationship: the infrastructure investments now coming online are larger, both absolutely and relatively, than any previous training run increase.
Second, model capabilities will increasingly cross thresholds that feel qualitatively different to users. A model that can reliably plan and execute multi-hour research tasks, maintain coherent context over days of interaction, and reason through genuinely novel problems is not just a "better chatbot" — it changes the category of work that can be delegated to AI systems.
Third, the speed of iteration is accelerating. Labs are now shipping meaningful capability updates every two to three weeks, not every six to twelve months. This compressed release cadence means that by the time users and enterprises have adapted to one capability level, the next is already arriving.
The Investment Thesis and Its Risks
Morgan Stanley's note is ultimately an investment document, and the implicit thesis is clear: the AI infrastructure buildout is justified by the capability returns it will generate. The firms building data centers, manufacturing GPUs, and training frontier models are making a bet that the scaling relationship holds and that the market for AI capabilities will absorb the output.
The risks are worth acknowledging. The 10x-to-2x relationship is empirical, not guaranteed. It could plateau, as many scaling relationships in engineering eventually do. The conversion of model capability into revenue is not automatic — enterprises and consumers need to find the new capabilities valuable enough to pay for them. And the energy, water, and environmental costs of the compute buildout are real and growing.
But if the relationship holds even approximately over the next two to three model generations, the implications for productivity, economic structure, and the nature of knowledge work are profound. Morgan Stanley is not given to hyperbole in its research notes. When they say investors should prepare to be shocked, the underlying analysis deserves serious attention.
Where I Stand
I have been tracking scaling laws and their implications for several years now, and my honest assessment is that we are in a period where the conservative position — "it will probably plateau soon" — has been wrong more often than the optimistic position. That does not mean scaling will continue indefinitely, and I remain alert to signs of diminishing returns. But the convergence of massive compute investment, architectural innovation, and accelerating research velocity suggests that the next 18 months will deliver capability gains that require us to update our priors about what AI systems can do.
The Morgan Stanley note is significant not because Wall Street analysts have special insight into AI research, but because it reflects what the labs themselves are telling their most important stakeholders. When the people building the systems tell the people funding the systems to brace for impact, the rest of us should at minimum pay attention.