
AWS announced it is deploying Cerebras CS-3 systems to deliver what it describes as the fastest AI inference available through Amazon Bedrock. The architecture is notable: AWS Trainium chips handle the prefill phase of inference while Cerebras's Wafer-Scale Engine handles the decode phase, achieving roughly five times the token throughput of conventional GPU-based inference. Meanwhile, Nebius raised $2 billion from Nvidia to build out its AI cloud infrastructure. These developments point to a significant structural change in how AI inference is delivered and what it costs.
I want to unpack what the AWS-Cerebras partnership means technically, why disaggregated inference architecture matters, and what the broader inference cost wars mean for the AI industry.
Understanding Disaggregated Inference
To understand why this architecture is significant, you need to understand the two distinct phases of large language model inference.
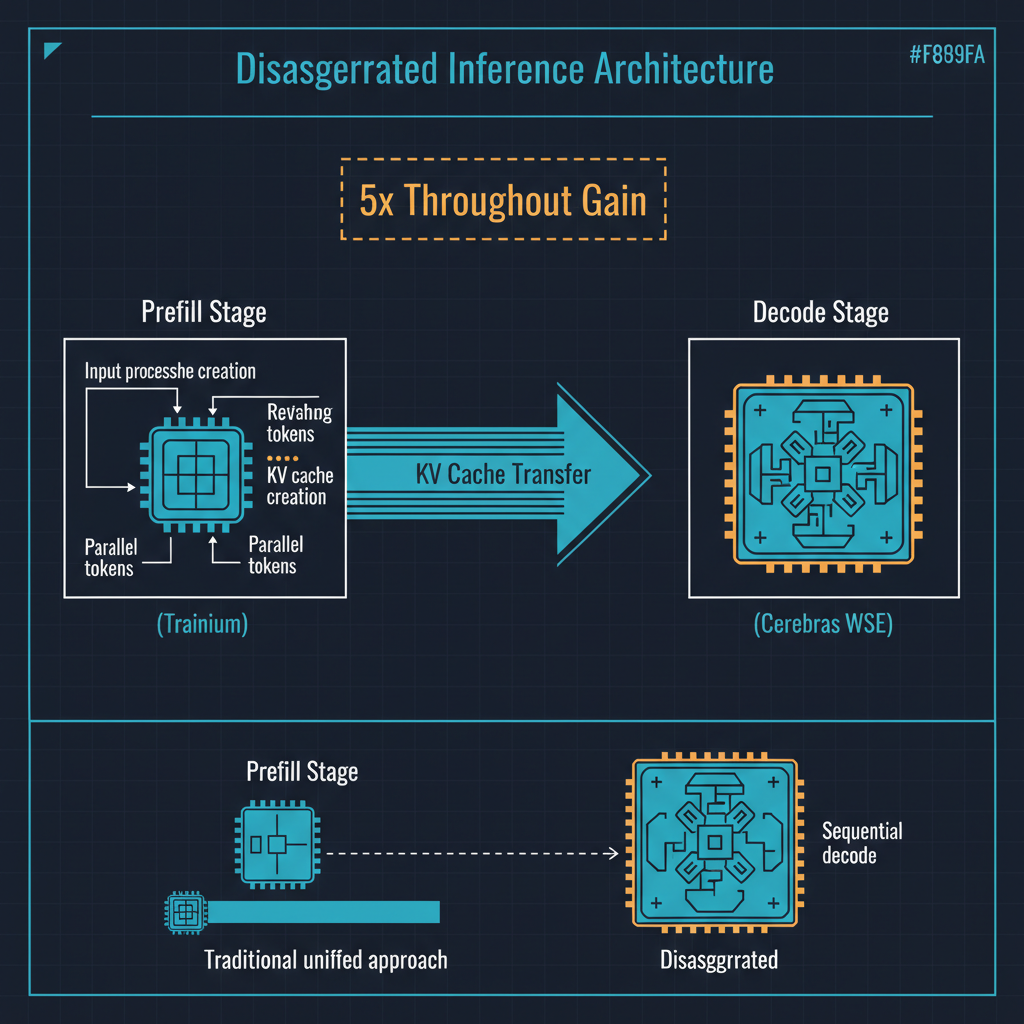
Prefill is the phase where the model processes your entire input prompt. Every token in your prompt must be processed to build the internal representations that the model will use to generate its response. This phase is compute-bound: the bottleneck is how fast you can run matrix multiplications across the model's parameters. It benefits from high-bandwidth, massively parallel compute, which is what GPUs and custom AI accelerators like AWS Trainium are designed for.
Decode is the phase where the model generates output tokens one at a time, each new token depending on all previous tokens. This phase is memory-bandwidth-bound: the bottleneck is how fast you can load model weights from memory for each token generation step. GPUs are not optimized for this pattern. They have enormous compute capability but relatively limited memory bandwidth relative to that compute, which means the GPU sits largely idle during decode, waiting for weights to be loaded from memory.
The insight behind disaggregated inference is simple but powerful: use different hardware for different phases. AWS Trainium, with its high compute throughput, handles prefill efficiently. Cerebras's Wafer-Scale Engine, which is a single chip the size of a dinner plate with 900,000 cores and 44 gigabytes of on-chip SRAM, handles decode with extraordinary memory bandwidth because the model weights sit in SRAM on the chip rather than in separate DRAM that must be accessed across a memory bus.
The result is a 5x improvement in token throughput compared to using GPUs for both phases. This is not an incremental improvement. It is a step change that alters the economics of AI inference.
Why Inference Economics Matter Now
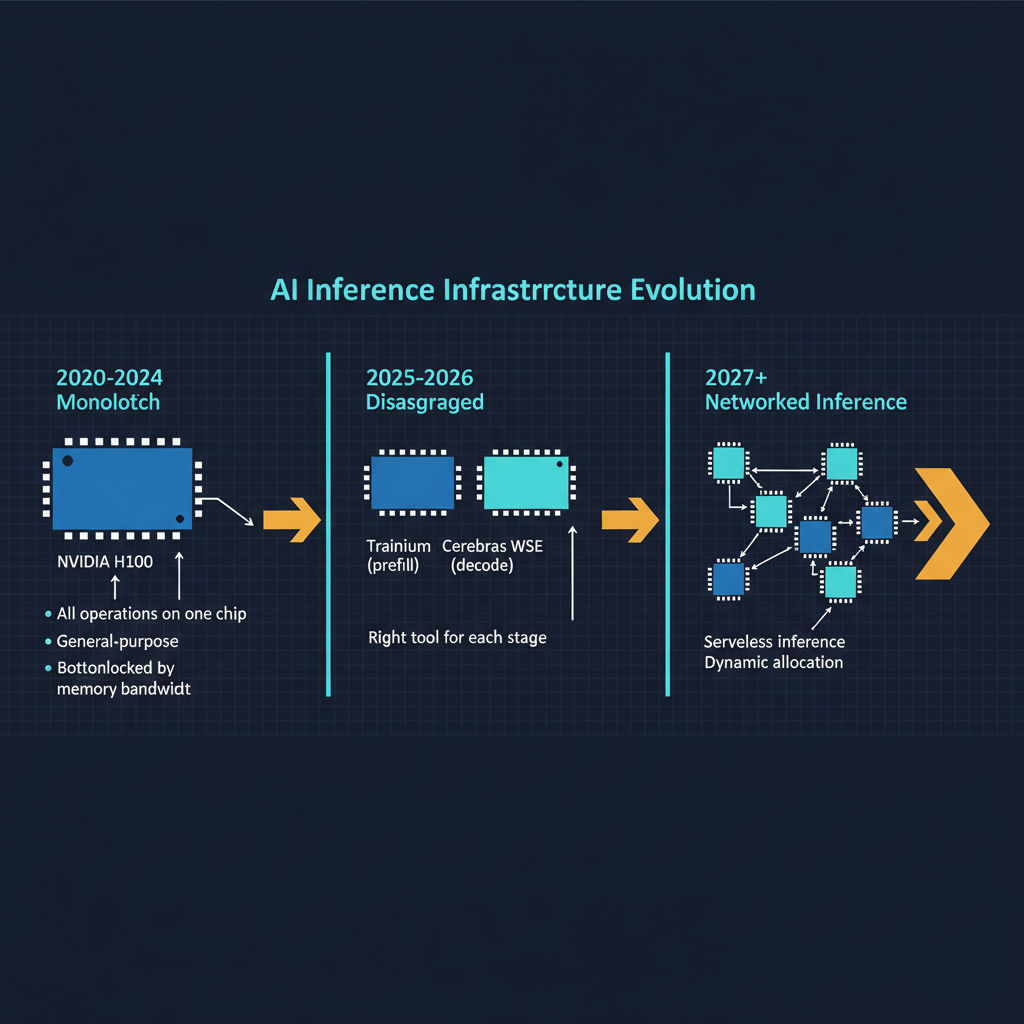
During the training era of AI from 2020 to 2024, the dominant cost concern was training compute. How many GPUs, how many weeks, how many millions of dollars to train a frontier model? Training costs drove the capital requirements of AI companies and determined who could compete at the frontier.
We have now entered the inference era. The frontier models have been trained. The primary cost for AI companies is no longer training new models but running existing models at scale to serve hundreds of millions of users and enterprise customers. OpenAI reportedly spends more on inference compute than on training. Anthropic's $19 billion revenue trajectory is driven by API consumption, which means inference. Google's Gemini is embedded in products used by billions of people, all requiring inference at every interaction.
The math is straightforward. If you can deliver the same quality inference at one-fifth the cost per token, you can either reduce prices to gain market share, maintain prices and dramatically improve margins, or serve five times as many users on the same infrastructure. All three options are strategically powerful.
This is why the AWS-Cerebras partnership matters beyond its technical elegance. It represents a potential shift in the competitive dynamics of AI cloud infrastructure.
Cerebras's Unusual Bet
Cerebras has been one of the more fascinating companies in AI hardware. While everyone else was designing chips and connecting them in clusters, Cerebras took the approach of building a single chip the size of an entire silicon wafer. The CS-3 contains 900,000 AI-optimized cores on a single piece of silicon, with 44 gigabytes of on-chip SRAM.
This architecture seemed like an engineering curiosity for years. Building wafer-scale chips is extraordinarily difficult from a manufacturing perspective, and the yield challenges are immense. But the architecture turns out to be nearly perfectly suited for the decode phase of LLM inference, precisely because on-chip SRAM eliminates the memory bandwidth bottleneck that constrains GPUs.
The AWS partnership validates Cerebras's architectural bet in the most commercially meaningful way possible. AWS is the world's largest cloud provider, and Bedrock is their managed AI service used by thousands of enterprises. Deploying Cerebras hardware behind Bedrock means that enterprise customers will benefit from the disaggregated architecture without needing to understand or manage the underlying hardware complexity.
The Nebius-Nvidia $2 Billion Raise
In the same period, Nebius raised $2 billion with significant investment from Nvidia to build out AI cloud infrastructure. Nebius, which emerged from Yandex's restructuring, is building GPU-centric data centers optimized for AI workloads. Nvidia's investment is strategic: more AI cloud providers means more demand for Nvidia GPUs.
The Nebius raise highlights the sheer scale of capital flowing into AI infrastructure. The market's appetite for AI compute appears insatiable, driven by the gap between current AI compute capacity and the projected demand from enterprise adoption, agent systems, and the scaling of consumer AI products.
But the Nebius investment also creates an interesting tension with the AWS-Cerebras story. Nebius is doubling down on conventional GPU-centric architecture. AWS is exploring disaggregated architectures with specialized hardware. These represent different bets on the future of AI infrastructure, and both are being funded at enormous scale.
The Inference Cost War
The AI inference market is entering a price war that will reshape the industry. Consider the competitive dynamics currently in play.
AWS is deploying Cerebras for disaggregated inference through Bedrock, potentially offering significantly lower cost per token. Google has custom TPU hardware with competitive inference economics and massive scale advantages. Microsoft and OpenAI are exploring custom hardware through Project Maia. Groq has built LPU (Language Processing Unit) chips specifically optimized for inference speed. SambaNova, Graphcore, and several other companies are pursuing specialized inference hardware.
The consequence of this competition is that inference costs will continue to fall rapidly. We have already seen dramatic reductions. The cost per million tokens for GPT-4-class models has dropped by roughly an order of magnitude since early 2024. Disaggregated architectures like AWS-Cerebras promise another step function reduction.
For AI application developers, falling inference costs are unambiguously positive. Applications that were economically unviable at $30 per million tokens become viable at $3 and become mass-market at $0.30. The reduction in inference costs expands the addressable market for AI applications in the same way that declining compute costs have historically expanded markets for every generation of technology.
For AI infrastructure providers, the picture is more complex. Falling prices per unit are only profitable if volume grows faster than prices decline. This is the classic cloud infrastructure dynamic, and it rewards scale. The providers with the most efficient infrastructure and the largest customer base will thrive. Those caught with expensive, undifferentiated infrastructure will face margin compression.
What I Am Watching
Latency, not just throughput. The 5x throughput improvement from disaggregated inference is compelling, but latency matters as much as throughput for many applications. If separating prefill and decode across different hardware adds network latency between phases, the user experience may suffer even as throughput improves. The engineering challenge is achieving both high throughput and low latency simultaneously.
The middleware layer. Disaggregated inference creates a need for intelligent routing and orchestration. Which requests should be routed to which hardware? How do you balance load across prefill and decode resources that have different capacity profiles? This middleware layer will become increasingly sophisticated and commercially important.
Custom silicon proliferation. The AWS-Cerebras partnership accelerates a trend toward specialized hardware for specific AI workload phases. We are moving from a world where Nvidia GPUs did everything to a world where different phases of AI computation are handled by different specialized processors. This is analogous to the evolution of data centers from general-purpose servers to specialized hardware for storage, networking, and compute.
The impact on model architecture. If decode-optimized hardware becomes widely available, model architectures may evolve to take advantage of it. Architectures that shift more computation to the decode phase, or that can be efficiently split across different hardware, would benefit disproportionately from disaggregated inference.
The Bigger Picture
The AWS-Cerebras partnership represents a maturation of the AI infrastructure market. We are moving beyond the era where "more Nvidia GPUs" was the answer to every AI infrastructure question. The future of AI inference is heterogeneous, specialized, and disaggregated, with different hardware optimized for different phases of computation and intelligent orchestration routing workloads to the appropriate resources.
This is good for the AI industry overall. Competition and specialization in inference hardware will drive costs down, which will expand the market for AI applications. It will make AI accessible to more organizations, enable new categories of applications that were previously too expensive to run at scale, and shift value creation from infrastructure providers toward application developers and end users.
The companies that understand this shift and architect their systems accordingly will have significant advantages. The era of AI inference is here, and the architecture that serves it is being built right now.


