
When Anthropic quietly updated Claude Opus to version 4.6 this week, the headline feature was a full one-million-token context window available at standard pricing -- no multiplier, no premium tier, no usage-based surcharge for long contexts. On the surface, this looks like a pricing decision. In practice, it is an architectural decision that changes how developers should think about building AI-powered applications.
I have been using Claude extensively in my own development workflows, and the shift from "context is expensive, use it sparingly" to "context is abundant, use it freely" is more consequential than it might appear. It removes a constraint that has shaped virtually every production AI system built in the last two years.
The Hidden Tax of Limited Context
To understand why this matters, consider how most AI applications are built today. The standard pattern involves a retrieval layer -- typically a vector database and an embedding model -- that selects relevant chunks of information to feed into the language model's context window. This retrieval-augmented generation architecture exists for two reasons: models could not hold enough context to process large documents directly, and even when they could, the cost of filling a large context window on every query was prohibitive.
The engineering overhead of RAG is substantial. You need an embedding pipeline, a vector store, a chunking strategy, relevance scoring, re-ranking, and constant tuning to ensure the retrieval layer surfaces the right information. When it works well, it is invisible to the end user. When it works poorly -- and it works poorly more often than most teams admit -- it produces the maddening experience of an AI that has access to your entire knowledge base but cannot find the answer to a straightforward question because the retrieval layer did not surface the right chunk.
With a million tokens at no premium, developers building applications against Claude can now ask a different question: do I actually need a retrieval layer for this use case, or can I just provide the full source material? For a surprising number of applications, the answer is the latter. An entire codebase, a full regulatory filing, a complete medical record, a multi-year email archive -- these often fit within a million tokens. The simplicity gain of removing the retrieval layer entirely should not be underestimated. Every piece of infrastructure you do not build is infrastructure you do not need to maintain, debug, or explain when it produces unexpected results.
What "No Premium" Actually Means Economically
Previous long-context models from various providers typically applied a multiplier -- often 2x to 4x -- for context windows beyond certain thresholds. This created a practical ceiling on how many applications could justify long-context usage. A summarization task that costs $0.02 with a 32K context becomes economically challenging at $0.08 with a 200K context, especially at scale.
Anthropic's decision to eliminate this multiplier for Opus 4.6 signals confidence in their infrastructure efficiency and, more strategically, a bet that encouraging high-context usage will expand the total addressable market for their API. If developers build applications that depend on million-token contexts, they become structurally committed to models that can deliver that capability reliably.
For developers and teams evaluating their AI infrastructure costs, the math has changed. Applications that were economically infeasible with premium long-context pricing may now be viable. I expect to see a wave of applications that were designed around context limitations being re-architected to take advantage of abundant context. This is not a trivial migration -- applications built around RAG pipelines have structural assumptions baked into their design -- but for new applications, the starting architecture should now default to full-context approaches where the data volume permits it.
Improved Coding Capabilities: The Understated Upgrade
Alongside the context window expansion, Anthropic highlighted improved coding capabilities in Opus 4.6. In my testing, the improvements are most noticeable in three areas: handling complex multi-file codebases, maintaining consistency across long editing sessions, and producing code that integrates correctly with existing project conventions rather than generating plausible but incompatible solutions.
This last point deserves emphasis. The most common failure mode I encounter with AI coding assistants is not that the generated code is wrong in isolation -- it is that it does not match the patterns, naming conventions, error handling strategies, and architectural decisions of the existing codebase. A function that works perfectly but uses a different error handling pattern than the rest of the project creates maintenance burden rather than reducing it.
With a million-token context, Claude can now hold an entire medium-to-large codebase in context simultaneously. This means it can observe and replicate project conventions without the developer needing to manually specify them. The code it generates is more likely to look like code that belongs in the project rather than code that was pasted in from a different project with a different style.
I have been running Opus 4.6 against several of my own projects with full codebase context, and the difference in output quality compared to working with partial context is immediately apparent. The model picks up on testing patterns, configuration conventions, and even commenting styles without being explicitly instructed. This is the practical value of large context windows in coding workflows -- not just that you can analyze more code, but that the model develops what amounts to project-specific awareness.
Implications for AI Application Architecture
The broader implication of abundant, affordable long context is a shift in the default architecture for AI applications. For the past two years, the standard stack has been: embedding model, vector database, retrieval pipeline, language model, and output formatting. This stack is battle-tested and well-understood, and it will remain the right choice for many applications -- particularly those working with corpora that exceed even million-token limits, or applications where precise source attribution from specific documents is critical.
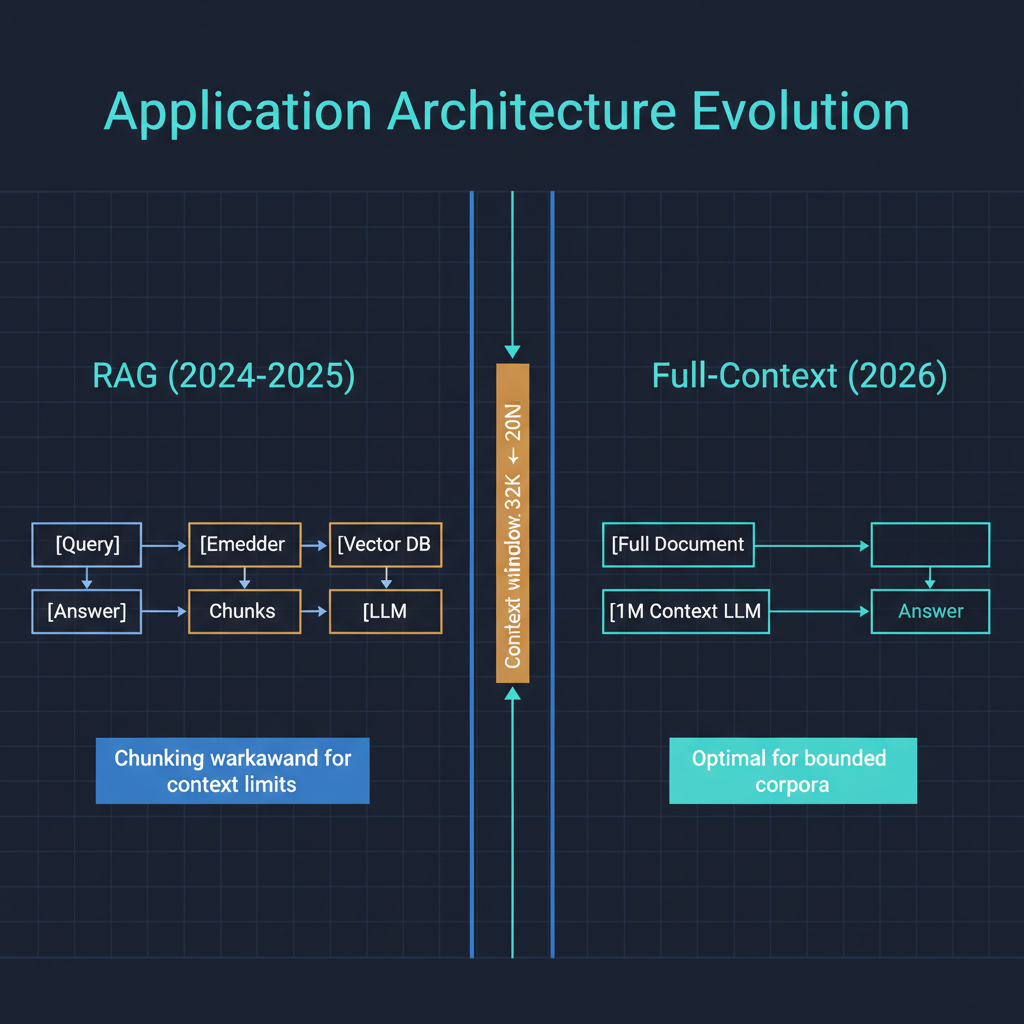
But for a large class of applications -- internal knowledge tools, code analysis platforms, document review systems, research synthesis tools -- the simpler architecture of "load everything into context and query directly" is now both technically feasible and economically viable. This is a meaningful reduction in system complexity, and simpler systems are easier to build, easier to debug, and easier to reason about.
The caveat is that long-context performance is not uniform across all models or all tasks. Needle-in-a-haystack retrieval from a million-token context is a different capability than coherent synthesis across a million tokens. Developers should evaluate their specific use cases rather than assuming that a larger context window automatically means better results for every task type.
The Competitive Landscape
Anthropic is not alone in pushing context boundaries. OpenAI's GPT-5.4 also ships with a million-token context, and Google's Gemini models have been offering extended context for some time. What distinguishes Anthropic's move is the pricing decision. By removing the premium, they are making a competitive statement: long context should be a standard capability, not a luxury feature.
This puts pressure on other providers to follow suit. If Claude offers million-token context at standard rates while competitors charge a multiplier, the total cost of ownership for long-context applications tilts significantly in Anthropic's favor. I expect we will see pricing adjustments from other providers within the next quarter.
Looking Forward
Claude Opus 4.6 is not a revolutionary leap in raw capability -- it is a strategic removal of constraints that have shaped how the entire industry builds AI applications. The million-token context at no premium, combined with coding improvements that leverage that context effectively, makes a compelling case for re-evaluating architectural assumptions.
For practitioners, my recommendation is straightforward: if you are building a new AI application and your data fits within a million tokens, start with a full-context architecture and add retrieval complexity only when you have evidence that you need it. The simplest system that meets your requirements is almost always the best system to operate.
The era of treating context as a scarce resource is ending. The applications we build next should reflect that.


