
Most agent frameworks make the happy path easy and the failure path impossible to reason about. You chain together a few calls, everything works in your demo, and then in production some tool returns an unexpected value at step 4 and your entire pipeline collapses with no state to recover from and no clean way to retry.
LangGraph takes a different approach, and it is one I have come to respect precisely because it forces you to think about state and control flow explicitly rather than hiding them behind abstractions.
The Core Insight: Graphs, Not Chains
LangGraph models agent workflows as directed graphs (technically, directed cyclic graphs — cycles are allowed and essential for agentic loops). Each node in the graph is a function that receives state, performs some computation (including LLM calls, tool invocations, or pure logic), and returns updated state. Edges define the control flow, including conditional edges that route based on the current state.
This sounds simple, but the implications are significant. Because state is explicit and typed, you always know what information is available at each node. Because control flow is declared as graph edges rather than buried in imperative code, you can visualize, test, and reason about your workflow as a structure rather than as execution traces.
The StateGraph is the core primitive. At its heart, you define a typed state schema — a structured dictionary that captures everything the agent knows at any point in its execution: the messages exchanged, the tool calls pending, how many iterations have elapsed, and the final answer if one has been produced. This explicit typing is what makes LangGraph workflows debuggable; every state transition is traceable rather than opaque.

The Annotated[list, operator.add] pattern is worth noting — it tells LangGraph how to merge state when multiple branches write to the same field. This is the kind of explicit design decision that prevents entire classes of concurrency bugs in parallel workflows.
Nodes and Edges
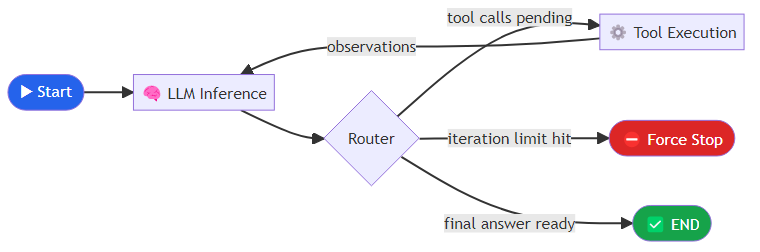
Nodes are plain Python functions. In a standard ReAct loop, you need at minimum two: one that invokes the LLM and records its response and any tool call requests, and one that executes those tool calls and records the results. A third function — the conditional edge router — inspects the current state and decides where to route next: to tool execution if tool calls are pending, to a forced termination if the iteration limit has been exceeded, or to the end node if the model produced a final answer.
This pattern implements the standard ReAct loop (Reason, Act) but with explicit state tracking and a hard iteration limit — two things that most naive agent implementations skip and then regret.
Persistence and Checkpointing
The feature that separates LangGraph from simpler orchestration approaches is its checkpointing system. LangGraph can persist state at every node execution, which means:
- Resumable workflows: if your agent crashes at step 7 of a 15-step task, you can resume from the last checkpoint rather than starting over
- Human-in-the-loop: you can pause execution, present state to a human for approval, and resume when authorized
- Time-travel debugging: you can inspect the state at any historical point and re-run from there with different inputs
Enabling checkpointing requires attaching a saver to the compiled graph. For development, an in-memory SQLite saver works fine; each invocation is tagged with a thread_id that groups all checkpoints for a given task run. To resume a paused workflow, you retrieve the checkpoint history for the thread and pass a specific checkpoint identifier to the next invocation — the graph picks up exactly where it left off. In production systems, you replace the SQLite saver with a PostgreSQL-backed store; LangGraph ships with adapters for several databases, and the interface is consistent across backends.
Multi-Agent Patterns in LangGraph
LangGraph's graph model scales naturally to multi-agent systems. The two primary patterns are subgraphs and the supervisor pattern.
Subgraphs let you compose graphs hierarchically. A parent graph can invoke a child graph as a single node, with the child graph handling its own internal state. This is the right abstraction for specialized agents (a research agent, a code agent, a review agent) that you want to treat as black boxes from the parent's perspective.
The supervisor pattern uses a routing node that decides which specialized agent should handle the current state. A small classifier LLM inspects the current messages and returns a label — "code," "research," or "general" — which the conditional edge router maps to the corresponding specialized agent node. Each label maps to one branch of the graph; the routing is explicit and enumerable, which means any mismatch between the classifier's output and the declared edge names surfaces immediately as a detectable error rather than a silent wrong turn.
This pattern is simple and debuggable, which is why I prefer it to more dynamic swarm architectures for most production use cases.
Where LangGraph Struggles
LangGraph is not a panacea, and I want to be honest about its limitations.
Verbosity. Building even moderately complex graphs requires significant boilerplate. The explicit state typing and edge declarations that make LangGraph safe to reason about also make it verbose to write. Teams new to the framework consistently underestimate the initial setup cost.
Debugging parallel execution. LangGraph supports parallel node execution (via fan-out edges), but debugging failures in parallel branches is substantially harder than debugging sequential execution. The checkpointing helps, but the tooling for visualizing parallel execution traces is still immature.
Dynamic graph modification. LangGraph graphs are compiled at initialization time. If you need to dynamically modify the graph structure at runtime — adding nodes based on user input, for example — you are working against the framework's design. Some use cases genuinely require dynamic graph construction, and LangGraph is not the right tool for those.
LLM routing reliability. Conditional edges that rely on LLM outputs for routing decisions inherit all the reliability problems of LLM inference. If your routing node hallucinates an invalid edge name, you get a runtime error rather than a graceful fallback. Always validate LLM routing outputs against the set of valid next nodes.
Production Deployment Considerations
After deploying several LangGraph systems in production, a few lessons stand out:
First, design your state schema for observability. Include fields for error_count, current_node, start_time, and any task-specific metadata you will want to query later. State is your audit trail.
Second, every long-running workflow needs a budget. Add max_iterations, max_tool_calls, and timeout_at to your state schema and enforce them in conditional edges. Agents that can loop indefinitely will eventually loop indefinitely.
Third, use interrupts strategically. LangGraph's interrupt_before and interrupt_after mechanisms let you pause execution at specific nodes for human review. Use them at high-stakes action points — before sending emails, before modifying databases, before committing code — rather than trying to catch problems after the fact.
LangGraph is currently the most production-ready framework for stateful agent workflows. It is not the simplest to learn, but the explicitness it demands is exactly what saves you when things go wrong at 2am in production. That trade-off, in my experience, is almost always worth making.
Explore more from Dr. Jyothi


