Every conversation about agent automation eventually arrives at the same question: "At what point can we remove the human from the loop?" The question usually comes from a reasonable place — humans are expensive, slow, and inconsistent; the whole point of automation is to do more with less. But the framing reveals a fundamental misunderstanding of what human oversight actually provides.
Human oversight in AI systems is not a temporary workaround for insufficient model capability. It is a design feature that provides properties that no current AI system can self-provide: accountability, contextual judgment under genuine uncertainty, and the ability to course-correct when the entire system — including its evaluation criteria — is wrong.
Let me be precise about what this means and what it does not.
What Human Oversight Actually Provides
Accountability and authority. Certain decisions carry legal, ethical, or organizational accountability that cannot be delegated to software. A medical diagnosis, a loan approval, a legal brief, a personnel decision — these are not just information products; they are acts that attach responsibility to a decision-maker. Current AI systems cannot hold responsibility. Until that changes (and it is not a technical problem — it is a legal and philosophical one), some decisions need a human in the loop simply because someone needs to be accountable for them.
Detection of systematic failures. When an AI system fails in a random, uncorrelated way, statistical aggregation reveals the failure. When it fails systematically — consistently biased in a particular direction, consistently wrong about a particular class of inputs — automated quality metrics often fail to detect it because the metrics were designed under the same assumptions the system violated. Human oversight provides a heterogeneous evaluation layer that can detect systematic failures that automated evaluation misses.
Genuine uncertainty handling. AI systems can express calibrated uncertainty about specific predictions within the scope of their training distribution. They cannot express meaningful uncertainty about whether the task they were given is the task they should be doing, or whether their evaluation criteria are appropriate for the current situation. That kind of meta-level uncertainty requires genuine contextual judgment that comes from human experience and stakes.
Value alignment under novel conditions. The alignment problem is not just about getting AI systems to follow rules — it is about getting them to apply values appropriately in situations the rule designers did not anticipate. Novel situations that fall outside the training distribution are exactly where AI systems are least reliable and human judgment is most valuable.
The Spectrum of Human Involvement
Human-in-the-loop is not binary. There is a rich spectrum of involvement patterns, each appropriate for different risk profiles and capability levels.
Human-on-the-loop (asynchronous oversight): The AI system operates autonomously, but human monitors review actions, outputs, and metrics. Humans can intervene but are not required for each action. This is appropriate for high-volume, low-stakes, reversible operations where errors can be detected and corrected in batch.
Human-in-the-loop (synchronous oversight at decision points): The AI system pauses at predefined checkpoints and presents a decision to a human. The human approves, rejects, or modifies before the system continues. This is the standard model for high-stakes irreversible actions.
Human-on-the-side (consultation on demand): The AI system operates autonomously but can escalate to human review when it detects low confidence or high-stakes conditions. This requires the system to have reliable uncertainty quantification — which is currently one of the weaker properties of large language models.
Human-as-validator (post-hoc review): Humans review AI outputs after the fact, providing feedback that improves the system over time. This is appropriate when errors are costly but not catastrophic, and when the human review loop is fast enough to catch systematic errors before they accumulate.

Implementing Meaningful Oversight in Agent Workflows
The challenge is implementing human oversight in ways that are actually useful rather than theatrical. A human who rubber-stamps every AI decision is not providing oversight — they are adding latency and creating false accountability. Effective oversight requires that the human have enough context, capability, and authority to meaningfully evaluate and override what they are reviewing.
In LangGraph, the interrupt mechanism provides a clean way to implement synchronous human checkpoints. The workflow is structured so that a node prepares the intended action in full — assembling all the details a human reviewer would need — but stops short of executing it, setting a flag that indicates the workflow is waiting for approval. A routing function reads that flag and directs the graph to an "awaiting human" node before anything irreversible happens. The graph is compiled with an explicit instruction to pause before reaching that node, and the current state is persisted to a checkpoint store so it survives any process interruption during the review window.
When the graph reaches the awaiting_human node, execution pauses. The state is persisted. A human can inspect the pending action via the state API, approve or modify it, and resume execution by updating the checkpoint with their decision and any notes, then invoking the graph again from where it left off.
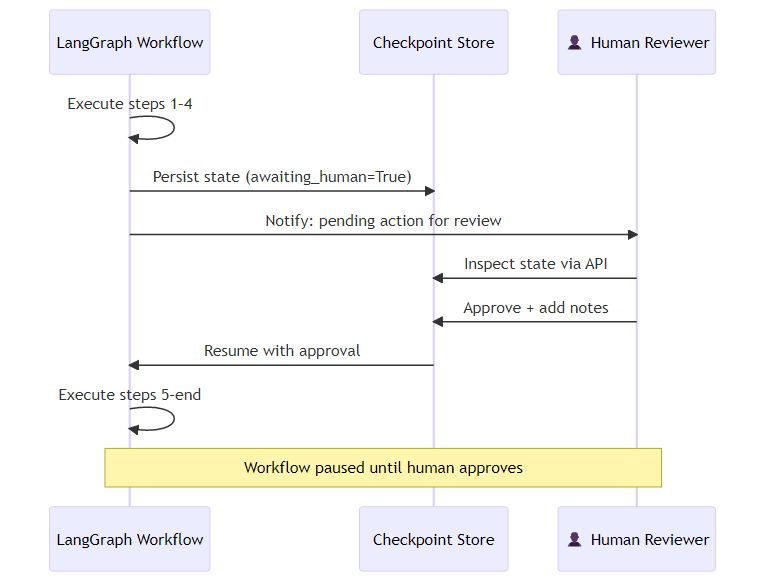
This pattern ensures that the human review is not decorative — the system literally cannot proceed without it.
Calibrating Oversight Intensity to Risk
Not every action warrants the same level of oversight. A principled approach to oversight calibration considers two dimensions: the stakes of the action (measured by the severity of potential negative outcomes) and the reversibility (whether a wrong action can be undone without significant cost).
High stakes + low reversibility: mandatory synchronous human approval before action High stakes + high reversibility: post-action review with rollback capability Low stakes + low reversibility: automated monitoring with human escalation on anomalies Low stakes + high reversibility: full automation with audit logging
The problem in practice is that these categories shift over time. An action that was low-stakes yesterday (like modifying a configuration file in a test environment) becomes high-stakes when the agent gains access to production systems. Oversight calibration needs to be dynamic and tied to the current permission context, not hardcoded at design time.
The Automation Bias Problem
There is a well-documented human factors problem in semi-automated systems called automation bias: humans who oversee automated systems tend to over-trust the system's outputs, especially when the system presents high-confidence recommendations and the human is reviewing many decisions quickly.
A human reviewing 200 AI-generated decisions per hour is not providing meaningful oversight of each decision. They are providing a rubber stamp with added latency. Meaningful oversight requires: manageable review volume, sufficient context to evaluate the decision, clear criteria for what makes a decision acceptable, and genuine authority and incentive to reject.
If your human review process does not meet these criteria, you have oversight theater rather than oversight. And oversight theater is worse than full automation in some respects — it creates the appearance of accountability without the substance.
Where the Research Points
Recent work on "human-AI teaming" (a term I prefer to "human-in-the-loop" because it emphasizes collaboration rather than oversight) suggests that the most effective designs are those where AI and human capabilities are complementary rather than hierarchical.
A 2024 study in Science examining AI-assisted decision-making in radiological screening found that human-AI teams performed better than either humans alone or AI alone — but only when the AI's uncertainty estimates were well-calibrated and the human interface made disagreement between human and AI judgment salient rather than hiding it. When the interface nudged toward AI agreement (by showing the AI's recommendation prominently), human performance degraded below what it would have been without AI assistance.
The design implication: oversight interfaces should be designed to preserve human judgment rather than replace it. Showing the AI's conclusion prominently, with confidence scores, before the human has formed their own view, undermines the independence that makes human oversight valuable.
Agents are becoming more capable. The answer is not to remove humans from the loop as capabilities improve — it is to redesign the human role from reviewing every action to setting policy, auditing outcomes, and handling the genuine edge cases that automated systems cannot resolve. That is a different kind of involvement, but it is not less involvement. It is more strategic involvement. And as the decisions AI systems are trusted to make become more consequential, the human role in governing those systems becomes more important, not less.
Explore more from Dr. Jyothi